Apache Flume
Összefoglalás
Az olvasó ebből a kombinált videó és olvasóleckéből gyakorlati tudást szerezhet az Apache Flume rendszer felépítéséről, valamint alapvető felhasználásának módjáról. Áttekintjük az eszköz architekturális felépítését, valamint az alapvetően támogatott komponenseit. Több konkrét példa konfiguráció segítségével bemutatjuk, hogyan használható a Flume különböző adat forrásokkal (hálózat, könyvtrá) és adatnyelőkkel (konzol, HDFS).A lecke fejezetei:- 1. fejezet: az Apache Flume eszköz felépítésének áttekintése, alapvető adatforrások és nyelők típusai (olvasó)- 2. fejezet: az Apache Flume eszköz telepítése, futtatása és Hello World példa beüzemelése (olvasó)- 3. fejezet: komoplexebb Apache Flume konfiguráció, HDFS sink bemutatása (videó)
 1. fejezet
1. fejezet
Az Apache Flume eszköz
Az Apache Flume egy elosztott, megbízható és nagy rendelkezésre állású szolgáltatás nagy mennyiségű napló adat gyűjtéséhez, egyesítéséhez és mozgatásához. Az architektúrája egyszerű és rugalmas, amely adatok folyamszerű átvitelére (stream) lett tervezve (lásd lenti ábra). A Flume robosztus, hibatűrő és megbízható számos beépített mechanizmus által. Egyszerű és könnyen bővíthető adatmodellt alkalmaz.
A Flume segítségével adat forrásokat (source) és adatnyelőket (sink) definiálhatunk, az adat forrásokból stream szerűen érkeznek az események, amelyeket egy csatorna az adatnyelőhöz vezet, ami eltárolja azt. A Flume számos adatforrást [1] és adatnyelőt támogat [2], ami persze bővíthető is. Számunkra a legérdekesebb a HDFS adatnyelő, amely tetszőleges stream forrás adatait valós időben tárolni tudja HDFS-re (lásd ábra). A Flume agent működéséről és a konfigurációjának módjáról a következő fejezetek tartalmaz további hasznos információt.
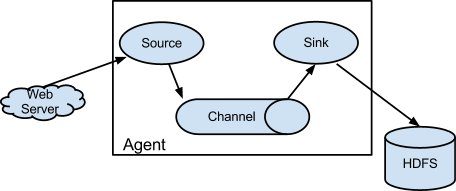
Flume alapvető működése
A Flume adatfolyam alapvető eleme az esemény (event), amely nem más, mint egy hasznos adatot tartalmazó bájtsorozat opcionális string attribútumokkal. A Flume ügynök (agent) egy JVM folyamat, amely futtatja a Flume komponenseket, amelyek segítségével a külső forrásból érkező események eljutnak a következő adat nyelőig (egy ugrás, vagy hop).
A Flume adat forrás elkapja és továbbítja azokat az eseményeket, amelyek valamilyen külső forrásból érkeznek hozzá, pl. egy web szervertől. A külső forrás olyan formátumban küldi az eseményeket a Flume adat forráshoz, amit az felismer. Azaz több speciális, előre implementált adat forrás típus és adatnyelő létezik, például egy Apache Avro [3] source az Apache Avro rendszer kliense által küldött, vagy másik vezeték Avro target-jéből származó eseményeket tudja kezelni. Amint egy Flume source fogad egy eseményt, azt azonnal egy vagy több csatornán (channel) továbbítja. A csatorna egy passzív tároló, amely addig tárolja az eseményeket, amíg azt egy Flume sink fel nem dolgozza. A fájl csatorna egy példa a csatornára, ami egy lokális fájlban tárolja az eseményeket. A sink eltávolítja az eseményt a csatornából és egy külső tárolóba helyezi, mint például a HDFS (a Flume HDFS sink segítségével), vagy továbbítja egy másik Flume source felé a következő Flume agent (következő ugrás, next hop) számára az folyamban. Egy ügynökön belül a forrás és nyelő aszinkron módon működnek, ahol a csatorna biztosítja az események pufferelését. A Flume tetszőleges ugrás számű komplex adatfolyamok definiálását is lehetővé teszi. További technikai részletekért tekintsük át a hivatalos dokumentációt [4].
A Flume által támogatott főbb adat források és nyelők típusai az alábbi két ábrán láthatók. Természetesen lehetőség van teljesen egyedi, saját forrás és nyelő implementálására is a megfelelő interfészek megvalósítása által.


2. fejezet
Apache Flume Hello World példa
Lássuk hogyan működik gyakorlatban az Apache Flume. Mielőtt telepítenénk a Flume ügynököt és létrehoznánk a megfelelő konfigurációt, indítsuk el a Docker alapú Hadoop klasztert, amit a 3g_BigData-hadoop-SPOC olvasólecke 1. fejezetében ismertettünk. Ezután lépjünk be a namenode container-re egy bash-t futtatva:
xxxxxxxxxx$ docker exec -it namenode bashErre a csomópontra fogjuk telepíteni az Apache Flume ügynököt kényelmi okok miatt (a HDFS fájlrendszert localhost-on keresztül elérjük), de más, tetszőleges hálózaton belüli gépre is telepíthető lenne. A telepítés menete:
- Töltsük le az Apache Flume-ot a következő URL-ről: https://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
xxxxxxxxxxroot@b055549cdaca:/# curl https://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz -o apache-flume-1.9.0-bin.tar.gz- Csomagoljuk ki a letöltött Flume disztribúciót
xxxxxxxxxxroot@b055549cdaca:/# tar xzf apache-flume-1.9.0-bin.tar.gz- Állítsuk be a
FLUME_HOMEkörnyezeti változót
xxxxxxxxxxroot@b055549cdaca:/# export FLUME_HOME=/apache-flume-1.9.0-bin- Teszteljük, hogy a Flume agent megfelelően működik a következő parancs segítségével
xxxxxxxxxxroot@b055549cdaca:/# $FLUME_HOME/bin/flume-ng versionAmennyiben látjuk a képernyőre kiírva, hogy Flume 1.9.0, a telepítés sikeres (a folyamatot az alábbi ábra mutatja).
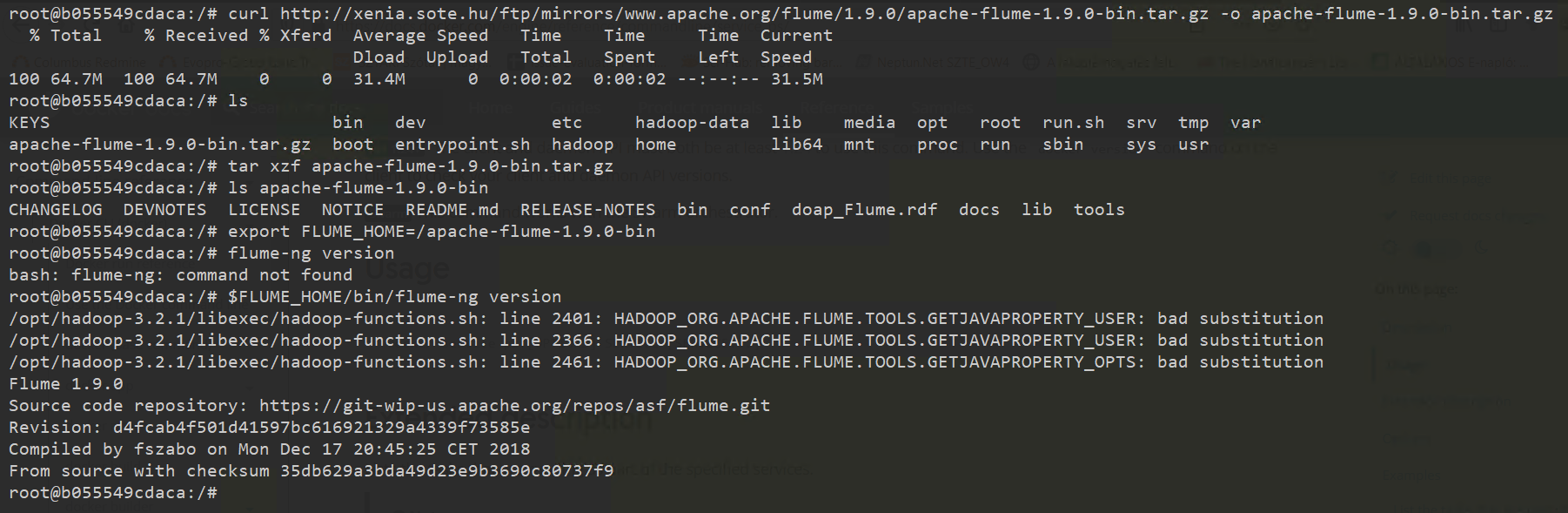
Sikeres telepítés után hozzuk létre az első Flume adat folyamunkat. Ehhez egy egyszerű ügynököt konfigurálunk be, amelyik a hálózat egy bizonyos portján figyeli az adatokat (netcat source), és minden ott beérkező üzenetet (event) a képernyőre ír ki egy konzol logger segítségével (logger sink). Az átviteli csatorna memóriában tárolja az eseményeket. Az example.conf tartalma legyen a következő (saját gépen tetszőleges szövegszerkesztővel készítsük el, majd másoljuk át a docker container-be).
x# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 44444# Describe the sinka1.sinks.k1.type = logger# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1
Miután elkészítettük a specifikációnak megfelelő Flume adatfolyam leírót, másoljuk át a fájlt a namenode docker container-be a megfelelő Flume konfigurációs könyvtárba:
xxxxxxxxxx$ docker cp example.conf namenode:/apache-flume-1.9.0-bin/conf/example.confEzután készen állunk arra, hogy elindítsuk az ügynök szolgáltatást (Flume agent service) a következő utasítással:
xxxxxxxxxxroot@b055549cdaca:/apache-flume-1.9.0-bin# bin/flume-ng agent --conf conf --conf-file conf/example.conf --name a1 -Dflume.root.logger=INFO,consoleA paraméterekkel megadjuk az agent nevét és a konfiguráció helyét, valamint mivel nincs log4j konfigurációnk, egy JVM paraméterrel beállítjuk, hogy konzolra történjen a log üzenetek kiírása (azaz az eventek kiírása). Az agent az elindulás után a namnode 44444-es portján figyel, és minden odaérkező üzenetet (event) elkap, majd acsatornán keresztül a sink felé továbbít, ami log üzenetben kiírja a kapott event-et. Tesztelés gyanánt nyissunk egy újabb terminál ablakot, és kapcsolódjunk a namenode container-hez a fenti módon, majd küldjünk egy Hello Wolrd! üzenetet a localhost:44444-es címre netcat program segítségével:
xxxxxxxxxx$ docker exec -it namenode bashroot@b055549cdaca:/# netcat localhost 44444Hello World!OKEnnek hatására az ügynököt futtató terminálban azt kell látnunk, hogy a konzolra log üzenetben kiíródott a Hello World! üzenet!
 3. fejezet
3. fejezet
Adat stream mentése HDFS-re
Ebben a fejezetben a HDFS sink-re koncentrálunk. Az alábbi videó lecke bemutatja, hogyan kell módosítani a 2. fejezetben összeállított Flume konfigurációt ahhoz, hogy a forráson érkező eseményeket ne egyszerűen kiírassuk logger-rel, hanem egyenesen HDFS-re tároljuk. A videóban használt konfigurációs állomány (example-hdfs.conf) az alábbi:
xxxxxxxxxx# example-hdfs.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 44444# Describe the sink HDFSa1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/testdataa1.sinks.k1.hdfs.rollInterval = 0a1.sinks.k1.hdfs.fileType = DataStream# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1
 További feladatok
További feladatok
- Készítsünk egy olyan Flume konfigurációt, ahol az adatok forrása egy könyvtár (
spool dir), ahonnan a fájlokat a Flume folyam HDFS-re tárolja!
- Módosítsuk úgy a fenti konfigurációt, hogy az adatok a syslog-ból érkezzenek!
- Készítsünk egy összetett Flume folyamot, ami két ügynököt kapcsol össze: A1:
syslog -> http, A2:http -> hdfs!
Referenciák
[1] https://data-flair.training/blogs/flume-source/
[2] https://data-flair.training/blogs/flume-sink/
[4] https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#the-plugins-d-directory