Reprezentáció tanulás
Minden gépi tanulási feladatban - legyen szó akár klasszikus, akár mély gépi tanulásról - a gépi tanulási mérnök feladata, hogy az egyedeket, az adott feladat számára hasznos, jellemzőkkel (jellemzővektorral) leírja. A jellemzőkinyrés lehet:
- szabályalap (minden feladathoz saját implementáció), vagy
- bizonyos adattípusokra standard jellemzőkinyerés (mint például szöveges dokumentumok esetén a szózsák modell), vagy
- használhatunk ún. bágyazásokat, amelyek a bemeneti adat egy vektor reprezentációját adják. Ez a vektor reprezentáció (beágyazás) a szóban forgó feladat adatbázisán kívüli adatok felhasználásával lett kialakítva.
A gyakoltban nagyon sokszor előfordul, hogy a konkrét feladathoz rendelkezésre álló címkézett adat (tanító adatbázis) egyszerűen túl kevés ahhoz, hogy egy szofisztikált jellemzőket tudjunk belőle kinyerni. Például ha a szózsák modell bigrammjai helyett csak a tényleges jelentéssel bíró szóösszetételeket akarjuk használni, ahhoz, hogy ezeket azonosítsuk/szűrjük sok adatra van szükségünk. Ilyen esetekben sokat segítenek a valamilyen külső adatforráson kialakított beágyazások. Ezek tipikusan több nagyságrenddel nagyobb adathalmazon lettek kialakítva és ezért szofisztikáltabb jellemzőleírást adnak, viszont mivel ezek nem az adott feladat adatbázisát használták ki, ezért ezek nem feltétlenül egyeznek meg ezek statisztikai jellemzőik.
Ebben az olvasóleckében reprezentáció tanulási megközelítéseket ismerünk meg. Ezek célja, hogy általánosabb adatformátumokra (képek, szövegek, audio, stb), nagy mennyiségű (általában) jelöletlen adatból tanuljanak egy olyan reprezentációt, ami egy egyedre az adott formátumban egy beágyazási vektort ad vissza. Ezek a beágyazás vektorok egy olyan reprezentációját adják a bemenetnek, ami nem a felszíni tulajdonságokat, hanem a tartalmi tulajdonságokat írják le, valamilyen látens/rejtett módon, azaz hogy pontosan hogyan reprezentáljuk az egyedeket egy fekete doboz, nem értelmezhető. A különböző megközelítések másként fogalmazzák meg azt, hogy mitől lesz egy beágyazás "jó", azaz mi lesz a reprezentáció tanulás célfüggvénye.
Önfelügyelt tanulás (self-supervised learning)
Az önfelügylet (self-supervision) alapötlete, hogy egy jó reprezentációnak biztosítani kell azt, hogy az egyed egy részéből megjósolható az adott egyed többi része. Például ha egy mondatban "letakarunk" (maszkolunk) egy szót, akkor a többi szóból meg kellene tudni jósolni, hogy melyik szót takartuk le. Építhetünk egy neurális hálózatot, ami címkézetlen adatokból (szövegekből, képekből) automatikusan állít elő tanító adatbázist, ahol a struktúra egyik részből kell megtanulnunk a többi részét predikálni (például úgy, hogy minden szót meg kell tudni jósolnunk néhány szavas környezetéből). Ez sem nem felügyelt gépi tanulás, mert nincs egy jól definiált célfeladat, és nem is felügyelet nélküli gépi tanulás, mert az automatikusan előállított tanító adatbázison utána felügyelt módon tanulunk. Azért hívjuk ezt önfelügyelt tanulásnak mert a tanuló önmagának állítja elő a tanító adatbázist. Ez az automata tanító adatbázis közel sem tökéletes, de ezt ellensúlyozza, hogy óriási mennyiségű tanító adatot tud előállítani a jelöletlen adatforrásokból.
Szóbeágyazások
Az egyik első sikere az önfelügyeletben tanult beágyazásoknak a word2vec volt 2013-ban. Itt van egy szótárunk (pl. a 80ezer leggyakoribb angol szó) és a célunk, hogy minden szótárelemhez egy sokdimenziós (pl. 100D) vektrot (\(w\)) rendeljünk, ami jó szóbeágyazást ad. Ehhez nyers szövegekből 5 szavas ablakokat veszünk ki (\(w_t\) a \(t\). szó egy mondatban) és egy neurális hálót tanítunk ezek felett. A Continuous Bag of Words Model (CBOW) egy osztályozási feladatként fogalmazza meg, hogy a megelező és rákövetkező két szó alapján meg tudjuk-e mondani, hogy a szótárból melyik szó a legvalószínűbb. A Skip-gramm modell egy szó alapján akarja megjósolni, hogy a szótárból melyik elem a legvalószínűbb előtte vagy utána. Ahhoz, hogy ezeket a predikciós feladatokat jó pontossággal meg tudjuk oldani olyan \(w\) vektorokra van szükségünk, amelyek a hasonló mondatkörnyezetekben előforduló szavakhoz hasonló vektorokat rendelnek.

Nagy nyelvi modellek
A word2vec szóbeágyazások egy szó jelentését statikus módon írják le, azaz egy adott szóhoz minden mondatkörnyeztben ugyanaz a beágyazás tartozik. A nagy nyelvi modellek (Large Language Model, LLM) nem egy szó jelentését, hanem hosszabb szövegek (egy mondat, egy bekezdés stb) jelentéstartalmának reprezentációját tanulják meg önfelügyelt tanulási módszerek segítségével. A szöveget itt is egy vektorral kódoljuk, és ennek a reprezentációnak az alapja itt is szóbeágyazások. Ezek a szóbeágyazások azonban már kontextusfüggőek, azaz a vár szóhoz más beágyazást rendelünk ha az igeként vagy főnévként szerepel az adott mondatban. A nagy nyelvi modellek a szavak kontextusfüggő beágyazásiból egy ún. transzformer neurális hálózati architektúra segítségével reprezentálják az egész szöveg jelentéstartalmát.
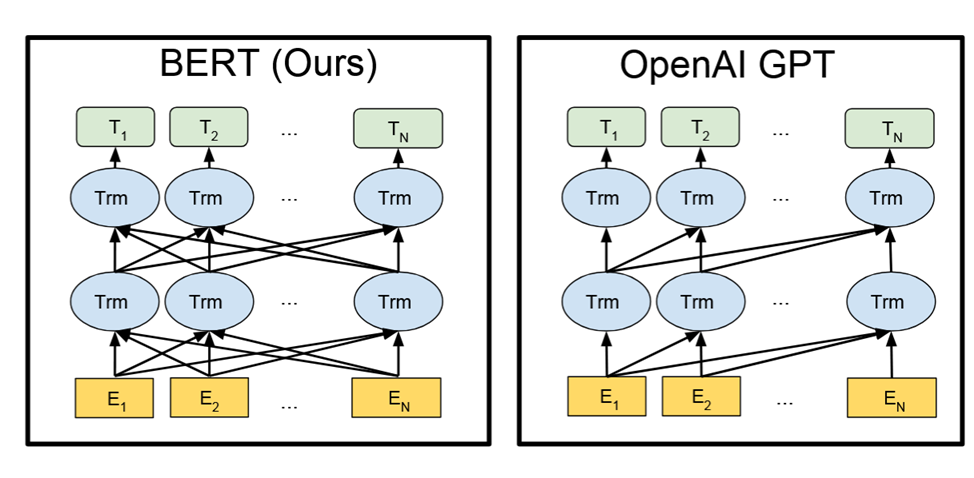
Az, hogy pontosan mi az önfelügyelt tanulási probléma az attól függ, hogy milyen jellegű feladatra akarjuk használni a nagy nyelvi modellt. Amikor egy szöveget akarunk elemezni (Natural Language Understanding) akkor előre ismerjünk a teljese szöveget, ami legyen most egy mondat. Ebben az esetben a kontextusfüggő beágyazások kiszámolása a mondat összes szavának figyelembevételével történhet (BERT típusú nyelvi modellek). Ekkor az önfelügyelt tanulási feladat ún. maszkolt nyelvi modellezés, ami azt jelenti, hogy letakarunk (maszkolunk) egy szót a mondatban és a többi szó alapján kell predikálnia a modellnek a maszkolt szót. Ehhez természetesen meg kell tanulnia jó kontextusfüggő szóbeágyazásokat.
Ha szövegeket akarunk generálni (Natural Language Generation) és nem meglévő szövegeket elemezni, akkor más fajta neurális hálózatra van szükségünk, hiszen ekkor a tanító adatbázisból csak a generálandó szó bal oldali környezetét ismerhetjük, a jobb oldali környezetét nem. Itt az önfelügyelt tanulási feladat egy "folytasd a szöveget" típusú feladat, azaz adott egy szósorozat és predikáljuk, hogy mi a legvalószínűbb szó, ami ez után következik. Természetesen ehhez is meg kell tanulnia a nyelvi modellnek a szöveg (prompt) reprezentációját és itt is transzformer neurális háló architektúrát használunk (GPT típusú nyelvi modellek).
Autoencoder
Az autoencoderek alapgondolata, hogy egy jó reprezentációból minimális vesztességgel visszaállítható az eredeti egyed. Egy encoder a nyers adatot egy kompaktabb (alacsonyabb dimenzis vektortérbe) reprezentációba képezi le, azaz tömöríti a bemenetet. Ebből a reprezentációból utána egy decoder hálónak minimális veszteséggel helyre kell állítani a bemenetet. Ha az encoder-decoder hálózat erre képes, akkor a tömörítés/reprezentáció megörzi, hatékonyan reprezentálja a bemenet tartalmát, és így a hálózat encoder része egy hasznos beágyazás lehet. Vegyük észre, hogy az autoencodereknek is csak címkézetlen adatokra van szüksége!

{kind=link}
Megjegyezzük, hogy az autoencoderek könnyen triviális megoldást képesek adni. Például minden példát "tömöríthetnek" egy egydimenziós vektorba, mondjuk az egyedek indexére. Ez a reprezentáció tömör és veszteségmentesen előállítja azokat az egyedeket, amiken az autoencoder tanítva lett, de nyilván nem ad hasznos beágyazást az adatbázison kívüli egyedekre. Ennek elkerülésére nagyon fontos, hogy az autoencodereket is regularizáljuk.
Reprezentáció felügyelt gépi tanulásból
Ha a saját feladatunkhoz nem, de az adott adattípushoz rendelkezésre áll nagy mennyiségű címkézett tanító adat, akkor ezen a külső adatbázison és egy külső feladaton tanított neurális hálóból is felhasználjuk az ott megtanult beágyazást. Neurális hálózatoknál az utolsó rejtett réteg a kimeneti neuronok előtt már tipikusan egy nagyon egyszerű réteg. Azért tud ez a hálózat jól működni mert a háló többi rétegében megtanult egy jó reprezentációt. Tehát levághatjuk a betanított hálózat utolsó, feladat-specifikus rétegét és a maradék háló egy olyan beágyazást ad, ami felett könnyen tanulható volt a külső feladat. Ezt a hálót használhatjuk a saját feladatunkon is beágyazásként. A képfeldolgozásban ez a reprezentáció tanulás a legelterjedtebb, mert ott rendelkezésre állnak nagy címkézett adatbázisrekordok (pl. az ImageNet 14 millió képet tartalmaz 22 ezer osztálycímkével).
Beágyazások használata a gyakorlatban
A bemutatott reprezentáció tanulási módszerek hatékony beágyazásokat tudnak adni, érdemes őket használni ha ezek rendelkezésre állnak:
- mások által betanítva (pre-trained) a tipikus adatformátumokon (kép, szöveg, audio, stb) vagy
- rendelkezésünkre áll a saját feladatunkhoz hasonló karakterisztikájú nagy mennyiségű címkézetlen adatbázis.
Nem szabad azonban elfelejteni, hogy ezek a beágyazások egy külső nagy adatbázis feladatához adnak jó reprezentációt, ami nem biztos, hogy mi a feladatunkban is megfelelő. Például az ImageNetben számos állatfaj található, mint célváltozó, a beágyazás állatfajok elkülönítéséhez ad egy nagyon jó reprezentációt. Ellenben viszont ha nekünk emberi arcokról kell érzelmeket azonosítanunk, akkor ez a beágyazás nem lesz hasznos.