Óriási mennyiségű adat érhető el vizuális (kép, videó) formában is. Ezen adatok automatikus feldolgozását képfeldolgozás (Image Processing) vagy gépi látás (Computer Vision) nevezzük.
Olyan algoritmusok fejlesztése amelyek képesek megérteni, hogy mi van egy képen vagy videóban ugyanolyan kihívásokkal teli probléma, mint a szövegek értelmezése.
A vizuális felismerés az ember számára természetes, de a gép számára nagyon nehéz, hiszen az nem fér hozzá az agyunkban lévő hétköznapi tudáshoz. Hasonlóan a szövegbányászathoz, a gépi látás is
máig megoldatlan probléma, azonban a képek és videók feldolgozásában és generálásában hatalmasat fejlődött a technológia az elmúlt évtizedekben.
Képfeldolgozási alkalmazások
Számtalan célalkalmazás van, ahol vizuális tartalmakat kell számítógéppel megértenünk és/vagy ember számára érthető vizuális tartalmat kell algoritmikusan generálnunk.
A teljesség igénye nélkül, néhány ilyen célalkalmazás:
Képosztályozás (image classification): előre adott kategóriák valemlyikébe kell egy ismeretlen képet besorolnunk. Például kutya vagy macska van a képen, vagy milyen
fajtájú kutya van a képen vagy egy emberi arcképről eldönteni, hogy milyen érzelmet fejez ki.
Kihívásokkal teli arcképek a bőrszín osztályozási feladatnál.Forrás: Alafif, ICMLA 2017
Objektum azonosítás és követés (object recognition and tracking): a feladat, hogy bizonyos típusú objektumokat azonosítsunk ("bekeretezzük") képeken illetve videókban kövessük ezek mozgását. Például egy önvezető autó számára
elengedhetetlen, hogy a kameraképén/lidaron a látható járműveket, gyalogosakat, forgalmi táblákat stb. azonosítani és követni tudjuk.
Az add-for.com objektum azonosítási demója.
Az Ultinous szegedi irodájában is objektum követésen dolgoznak.
Augmented reality: A cél, hogy valós képekre mesterséges objektumokat jelenítsünk meg. Ehhez pontosan kell azonosítani a látott képen
az objektumokat, hogy kiszámolhassuk hova lehet megjeleníteni az objektumot, hogy az valószerű legyen. A 3D objektumok generálásánál is figyelembe kell
vennünk a környezetet, hogy ahhoz legjobban illeszkedjen.
Három augmented reality alkalmazás.
Csak nagyon szűk alkalmazási területeken lehet szabályalapú rendszerekkel - erősen feladat-specifikus szabályokkal - megoldani a képfeldolgozási problémákat, mert az objektumok rengeteg féle formában
megjelenhetnek egy képen. Ezért az elmúlt évtizedben a képfeldolgozásban a gépi tanulási megoldások átvették a szabály alapú rendszerek vezető szerepét. A különböző célalkalmazások különböző gépi tanulási
feladatokra vezethetőek vissza. Ebben a leckében a legegyszerűbb feladattal, képek osztályozásával fogunk megismerkedni.
Képek előfeldolgozása
A képi tartalmakhoz kapcsolodó gépi tanulási feladatoknál is nagyon fontos az előfeldolgozás. Itt elsősorban a standardizálás a cél, azaz, hogy
a különböző típusú képeket egységes formátumra hozzuk, hogy a későbbi jellemzőkinyerés egyszerűbb legyen. A szövegbányászattal ellentétben, a
képfeldolgozásban, már a szükséges előfeldolgozási lépesek is nagyban függenek a célalkalmazástól, amit meg akarunk oldani.
A leggyakrabban alkalmazott előfeldolgozási lépések:
Képek egységes méretűvé alakítása nyújtással.
Színcsatornák egységesítésére is szükség lehet. Például ha szürkeárnyalatos (1 csatornás) képeink vannak, akkor a 3 színcsatornás képeket konvertálnunk kell.
Képosztályozási feladatnál gyakran valamilyen objektumot osztályozunk (pl. egy arc). Ilyen esetekben célszerű azonosítani a legkisebb magában foglaló téglalapot
az objektum körül és a felesleges képrészleteket levágni.
Jellemzőkinyerés képekből
A képosztályozási feladatoknál a kép egyedeket leíró jellemzőtér is nagyban problémafüggő. A teljesség igénye nélkül három nagy jellemzőkinyerési terület:
Amikor a képosztályozási feladatunkban az egész képet kitölti a célobjektum, akkor feltételezhetjük, hogy a standardizált képeken az egyes pixelpozíciókban hasonló
színárnyalatú pixeleknek kell lenniük az egy osztályba tartozó képeknél. Itt egy kézenfekvő megközelítés két kép között úgy definiálni a távolságot/hasonlóságot, hogy
az egyes pixelek páronkénti hasonlóságából aggregálunk egy mátrixhasonlóságot. Ilyen feladatok például az írott számjegyek felismerése (10 osztályos képosztályozási feladat)
vagy arcképek osztályozása ha a képet "kitölti" az arc.
Az MNIST számjegy felismerési feladat (10 osztályos képosztályozási feladat).Forrás: mdpi.com
A gépi tanulási keretrendszerekben pixelmártix helyett pixelvektorokkal dolgozunk (egyszerűen összefűzzük a pixelsorokat). Itt a jellemzőtér mérete a standardizált méretű
képek pixelszáma és a jellemző értéke a megfelelő pozícióban lévő pixel színárnyalata lesz. Ha az egyedeink ilyen módon vannak jellemzőkkel leírva, akkor célszerű olyan gépi
tanuló algoritmust választanunk ami egyed közti távolságfüggvényen alapul (lásd itt), hiszen itt a jellemzővektorok (azaz pixelmátrixok) közti hasonlóságot
bármilyen egyszerű vektorhasonlósággal leírhatjuk.
Teljesen más jellemzőleírásra van szükségünk, ha a képosztályozási feladatunk olyan, ahol a teljes kép színvilága meghatározó lehet. Ilyen például ha tengerparti vs túrázós nyaralós képeket akarunk osztályozni.
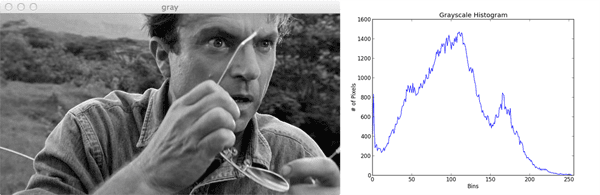
Ebben az esetben a kép globális színvilágát a pixelek színeinek hisztogramjával érdemes leírnunk. A jellemzőtér ebben az esetben a hisztogramot reprezentálja, azaz
egy dimenziós (szürkeárnyalatos) esetben a hisztogram intervallumai lesznek a jellemzők és az intervalum gyakorisága a jellemző értéke.
Színvilág hisztogram szürkeárnyalatos képből.Forrás: pyimagesearch.com
A globális színvilág hisztogram jellemzőtér esetén is a vektortávolság alapú gépi tanuló algoritmusok a jó választás, hiszen a két hisztogram hasonlóságára építjük az
osztályozó modellünket.
A képek mélyebb elemzéséhez szükségünk van alacsony szintű elemek, mint például élek azonosítására a képeken. Az ilyen egyszerű képelemek felismerésére a képfeldolgozás
algoritmusait használhatjuk. Ezek az algoritmusok képesek (gépi tanulás nélkül) kinyerni alacsony szintű elemek pozícióját, irányát és egyéb tulajdonságait. De akár maszkok
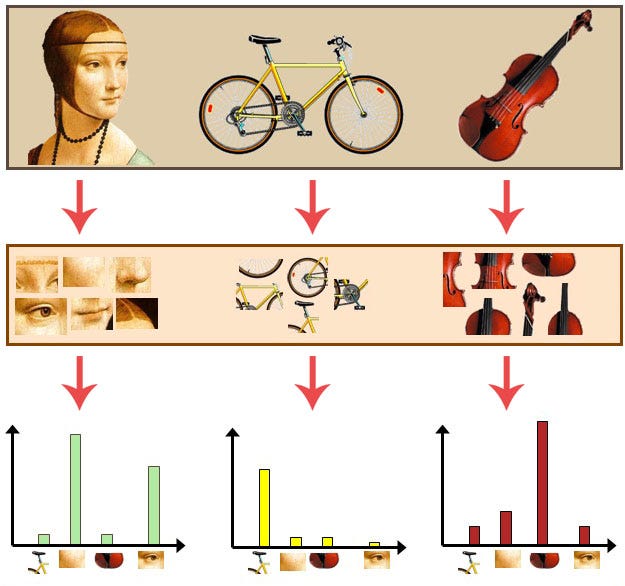
(pl. minden 5x5 pixelmátrix a képen) is lehetnek alacsony szintű elemek. Ezekből az alacsony szintű elemekből fogalmazhatunk meg jellemzőket a szózsák modellhez hasonlóan, azaz
az minden az adatbázisban előforduló alacsony szintű elem alkotja a "vizuális szótárat" és minden kép egyedhez a jellemző értéke az adott vizuális elem előfordulásának száma a képen.
A szózsák modell analógiája miatt ezt a jellemzőteret hívják bag-of-visual-words (BOVW)-nek is.
bag of visual words (BOVW)Forrás: towardsdatascience.com
Ellenörző kérdések
Milyen jelenségek okoznak gondot az első képen az algoritmikus bőrszín osztályozásnál?
Az SzTE Digitális képfeldolgozás gyakorlat kurzusa és tananyagai mélyen tárgyalják a képek előfeldolgozásához és jellemzőkinyeréshez szükséges technológiákat.
Képek gépi tanulás célú előfeldolgozásáról bővebben egy blog post
Színvilág hisztogram több színcsatornás képekből is kinyerhető. Lásd blog post
Kitekintés: Az elmút 10 évben a képosztályozásban mindent visz a Convolutional Neural Network (CNN), ami a deep learning egyik legnagyobb sikersztorija! Ez egy jó tutorial.