A számítógépes
beszédfelismerés alapjai
– lehetőleg matek
nélkül –
1.
A statisztikai alakfelismerés alapjai
A számítógépes
beszédfelismerés az ún. osztályozási feladat egy speciális esete: adottak
valamilyen objektumok, amelyeket valamilyen „jellemzőkkel” írunk le, és
ezeken az objektumokon definiálva van egy osztályozás, azaz adott osztályoknak
egy halmaza, és mindegyik objektum valamelyik osztályba tartozik. Az
osztályozási feladat célja egy olyan eljárás találása, amely az objektumok
közül lehetőleg minél többnek az osztályát képes eltalálni az objektum
jellemzői alapján.
Példa: Objektumok lehetnek például a kiejtett
beszédhangok. Ha ezeket digitálisan rögzítjük, akkor a számítógép számára egy
köteg számként fognak megjelenni – ezek lesznek esetünkben a jellemzők.
Végezetül, az osztályok lehetnek az adott nyelv fonémái. Az osztályozási
feladat tehát abból áll, hogy a kiejtett hangról, pontosabban az abból kapott
számítógépes reprezentációról el kell dönteni, hogy milyen fonéma.
Az osztályozási feladat
egy lehetséges matematikai formalizálása az ún. Bayes-döntéselmélet, amely a
valószínűségszámítás eszköztárát használja. Az ún. Bayes döntési szabály
azt mondja ki, hogy ha objektumokat kell a fent leírt módon osztályoznunk,
akkor hosszú távon akkor követjük el a lehető legkevesebb hibát (azaz
téves besorolást), ha mindig azt az osztály választjuk, amelyik az adott mérési
adatok alapján a legvalószínűbb.
A józan parasztésszel
is egybevágó, roppant egyszerű Bayes döntési szabályt az teszi igazán
vonzóvá, hogy matematikai garanciát ad a döntés (a fenti leírt értelemben vett)
optimalitására. Azonban, mivel a döntési szabály az egyes választási
lehetőségek valószínűségére épít, ezeket a valószínűségeket
ismernünk kell a döntéshozáshoz. A legtöbb esetben a valószínűségek
ismeretlenek, és ezért nagymennyiségű példa alapján becsüljük őket.
Itt jön be a képbe a gépi tanulás nevezetű tudományág, valamint a
statisztika, amely amúgy is közeli rokona a valószínűségszámításnak. Mivel
maga a Bayes döntési szabály elég egyszerű, a statisztikai alapú
alakfelismerés lényegében a következő problémában csapódik le: hogyan
lehet a döntéshez szükséges valószínűségeket minél pontosabban megbecsülni
példák alapján?
Példa: Tegyük fel, hogy beszédhangokról kell eldöntenünk, hogy magánhangzók
vagy mássalhangzók-e. Ehhez egyetlen mérési adat avagy „jellemző” áll
rendelkezésünkre: a hang erőssége, két lehetséges értékkel megadva: ‘halk’
vagy ‘hangos’. Tegyük fel továbbá, hogy van néhány, mondjuk 20 példánk. Ezek
mindegyikénél meg van adva, hogy magánhangzók vagy mássalhangzók voltak-e,
továbbá halkak vagy hangosak. Azaz adott húsz darab (hangos, mgh),(halk,
mhs),(halk, mgh),… alakú pár. Ebből a húsz példából könnyen tudunk
készíteni egy kis táblázatot, egyszerűen megszámolva, hogy az értékek
egyes kombinációi hányszor fordultak elő:
|
|
Halk
|
Hangos
|
Magánhangzó
|
3 |
10 |
Mássalhangzó
|
5 |
2 |
Ha az egyes
cellák számát elosztjuk az összes példa számával, (azaz 20-szal), akkor rögtön
megkapjuk a lehetséges kombinációk valószínűségének egy becslését. Az így
kapott táblázat értékeinek segítségével az osztályozás a következőképpen
működik: érkezik egy hang, amiről csak azt tudjuk, hogy halk vagy
hangos. Megkeressük a táblázat ennek megfelelő oszlopát, és abban
kiválasztjuk a maximális értéket tartalmazó sort. Jelen esetben minden hangos
hangra azt fogjuk mondani, hogy magánhangzó, és minden halk hangra azt, hogy
mássalhangzó, ugyanis az egyes oszlopokban ezek a legnagyobb
valószínűségűek.
2.
A statisztikai módszer ősellensége: a túl sok kombinációs lehetőség
A fenti kis táblázat elkészítése roppant
egyszerűnek tűnt. Azonban a gyakorlatban két gond is jelentkezik
ezzel kapcsolatban. Az egyik, hogy véges számú példa mindig félrevezető
lehet az objektumok valódi eloszlásával kapcsolatban (kihúzhattuk volna a 20
példát olyan szerencsétlenül is, hogy mondjuk nincs közte egyetlen halk hang
sem. Ekkor a táblázat első oszlopában csupa nulla állna…). A másik, még
nagyobb probléma, hogy a valóságban a táblázat mérete, azaz a lehetséges
kombinációk száma jóval nagyobb. Ugyanis a gyakorlatban többnyire nem csak
egyetlen mérési adatunk szokott lenni, és az adatok nem csak két értéket
vehetnek fel. És sajnos a táblázat mérete a jellemzők számának
exponenciális függvénye, azaz újabb mérési adatok bevételével ugrásszerűen
nő. Például ha 9 jellemzőnk lenne, mindegyik 2 lehetséges értékkel, a
táblázat máris 1024 cellából állna (figyelembe véve, hogy 2 osztály van)! Ez
természetesen rendkívül megnehezítené a cellák értékének becslését, például a
fenti 20 példa esetén a cellák jórésze üresen maradna. A szakirodalom a
statisztikakészítésnek ezt a kerékkötőjét „curse of dimensionality”-nak
nevezi. A kifinomult matematikai módszereken túl – amelyek ismertetésétől
itt eltekintünk – alapvetően háromféle módon lehet megpróbálni enyhíteni a
túl sok dimenzióból eredő gondokat:
– A példák számának növelése
mindig csak javíthat a becslés pontosságán. A beszédfelismerés esetén ez azt
jelenti, hogy minél nagyobb beszédkorpuszokat kell készíteni.
– Megkísérelhetjük
csökkenteni a jellemzők számát az esetleg irreleváns jellemzők
eldobásával. A lehetőleg minél kevesebb jellemzőből álló, de
azért a döntéshez szükséges minden fontos információt tartalmazó
jellemzőkészlet megtalálása a beszédfelismerőknél az úgynevezett
előfeldolgozó avagy „front-end” feladata.
– A valószínűségek felbontása. Nem kell az irdatlan méretű
táblázat minden elemét megbecsülnünk, ha a cellák elemei között valamilyen
összefüggés áll fenn, pl. ha valamely cellák értéke egyértelműen
meghatározza valamely más cellák értékét. A valószínűségszámítás ismer egy
nagyon alapvető ilyen esetet, ez pedig a jellemzők függetlensége
esetén áll elő. Ez akkor áll elő, ha valamelyik jellemző értéke
sosem befolyásolja egy másik jellemző értékét, és viszont. Ilyenkor a két
jellemző valamely érték-párjának előfordulási valószínűsége
egyszerűen a külön-külön való előfordulásuk valószínűségének
szorzata. Ily módon a nagy, együttes táblázat helyett egy csomó
nagyságrendekkel kisebb táblázat értékeit kell megbecsülni. Ezt a szorzat-alapú
felbontást több ponton is alkalmazzák a beszédfelismerésben. Hangsúlyozni kell
azonban, hogy a függetlenséget nem szokás matematikai úton igazolni, hanem
általában beérjük valamilyen „intuitív” magyarázattal. Sőt, sokszor úgy
használjuk a szorzat-szabályt, hogy közben tökéletesen tudatában vagyunk a
függetlenségi feltevés érvénytelenségének.
3.
Egy általános célú beszédfelismerő felépítése és működése
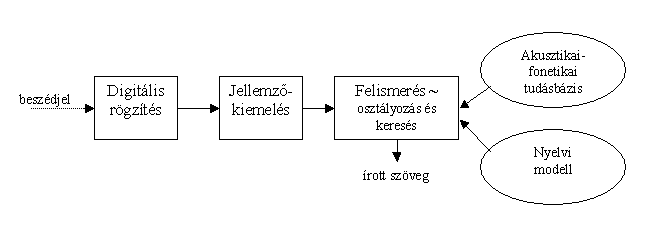
a, Az
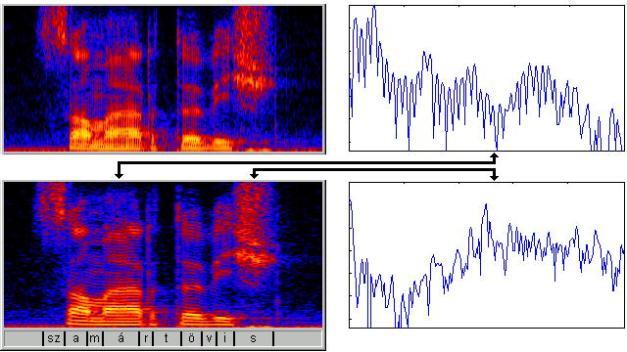
előfeldolgozó modul. Feladata a beszédjel elemzése és leírása számokkal. Az elemzés
leghagyományosabb módja az ún spektrogram, amely a jelen spektrális elemzést
végez. Az alábbi ábra a „szamártövis” szó spektrogramját mutatja, két
különböző beállítás esetén (ún. szélessávú ill. keskenysávú spektrogram).
Utóbbiból egy-egy metszetet külön is kirajzoltunk, egy zöngés és egy zöngétlen
hangból.
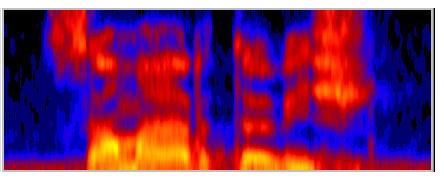
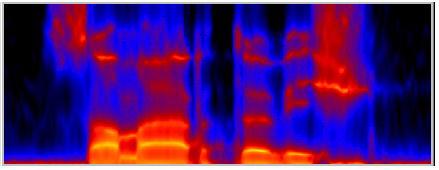
Ahogy már említettük,
fontos, hogy a beszédet minél kevesebb számadattal írjuk le. Ezért a
spektrogramból eltávolítanak minden olyan részletet, amely a felismerés
szempontjából nélkülözhetőnek tűnik. Az alábbi két ábra azt
szemlélteti, hogy mi marad a ”szamártövis” szó spektrumából két elterjedt
előfeldolgozási technika, a kepsztrum ill. a LPC alkalmazása után.
Technikailag a feldolgozás a beszédjel kis, 10-30
ezredmásodperces darabkáin, ún. „keretein” történik. Az egyes keretek
feldolgozásából kapott adatokat úgy tudjuk elképzelni, mint a spektrogram
egy-egy oszlopát.
Alapvetően kétféle információforrásunk van arra
nézve, hogy a fonetikai információ hogyan van kódolva a spektrumban. Az egyik
ilyen forrást az emberi hallás működésével kapcsolatos ismereteink
jelentik. A jelenlegi előfeldolgozó eljárások figyelembe is veszik az
emberi hallás legfontosabb tulajdonságait. A másik forrás a fonetika/fonológia.
E tudományágnak vannak elméletei arról, hogy az egyes beszédhangokat
meghatározó fonetikai jegyeket milyen ún. akusztikus kulcsok kódolják a jelben.
Azonban az automatikus beszédfelismerésben sajnálatos módon ezt a tudást nem
szokás kihasználni, és csak néhány kutató próbálkozik az ilyen elvű
technológiákkal. Ez részben a tudományágak közti rossz kommunikációval
magyarázható, részben pedig azzal, hogy a fonetikai eredmények sok szempontból
hiányosak, illetve vitatottak.
b, Az akusztikai-fonetikai modell. Ennek az egységnek a célja az akusztikai
jellemzők és a fonetikai egységek közötti kapcsolat leírása. Fonetikai
egységként legtöbbször a fonémákat szokás használni, habár előfordulnak
szó- és szótag-alapú rendszerek is. Továbbá, mivel a fonémák hajlamosak nagy
mértékben hasonulni a szomszédos hangokhoz, ezért általában a fonémák „stabil”
középső részén kívül a két átmeneti részt is külön egységként kezeljük.
Azaz, a hagyományos /a/, /b/, /c/ stb. fonémákon kívül külön fonetikai
egységnek tekintjük az /a b előtt/, /a b után/ stb. kombinációkat, minden
lehetséges párra. Ezzel a felbontással a folytonos beszéd minden fonémája
nyilván három részre bomlik: a középső stabil, és a két átmeneti
szakaszra.
A kiválasztott
fonetikai egységek (legyenek akár szavak, szótagok, fonémák avagy
fonéma-harmadok) és a lehetséges akusztikai megjelenésük közötti kapcsolatot
kétféle módon lehet megadni.
A tudásalapú
megközelítés egy akusztikai-fonetikai szakembert igényel, aki szabályok
formájában leírja a két szint közötti kapcsolatot. Mint említettük, ez a
technológia nem terjedt el, illetve igazából kiszorította a (kellő
mennyiségű példa esetén) jóval megbízhatóbb statisztikai megközelítés. A
statisztikai módszer jelenleg gyakorlatilag az egyedül használt technológia; az
akusztikai mérések és a fonetikus egységek közötti összefüggések megtalálása ez
esetben az 1. fejezetben ismertetett módon zajlik.
A statisztikai módszerek közül mindenképpen külön
meg kell említenünk a domináns technológiát, az úgynevezett rejtett Markov
modelleket (angol rövidítéssel HMM). A HMM építőegységeit „állapotoknak”
hívják, és ezek többnyire megfelelnek az általunk fentebb leírt
fonéma-harmadoknak. Hogyan is működik a HMM? Tekintsünk ehhez egy kis
részletet a beszédjelből, azaz az ábra spektrogramjából néhány szomszédos
oszlopot, továbbá egy adott állapotot, mondjuk az /a/ fonémához tartozót. A
HMM-nek – mint minden statisztikai modellnek – meg kell mondania annak a
valószínűségét, hogy az adott beszédrészlet egy adott állapothoz tartozik.
A HMM itt alkalmazza a szorzás-szabályt először: ugyanis csak az egyes
lehetséges spektrum-oszlopok egyes állapotokhoz való tartozását modellezi, és a
teljes jelrészlethez tartozó valószínűséget ezekből szorzással kapja
meg. Magyarul, az adott részlet annyira /a/, amennyire minden oszlopa az. Ezen
kívül még egy további dolgot is modellez a HMM: az egyes egységek hosszát, azaz
annak a valószínűségét, hogy az adott állapothoz rendelt részlet pont
ennyi oszlopból áll. Erre az információra a teljes beszédjel leírásakor lesz
szükség.
c, A nyelvi modell. Ha egy hosszabb beszédjel érkezik, akkor az az akusztikus modell
építőelemeinek – fonémáknak, fonéma-harmadoknak – egy sorozatából áll. A
nyelvi modell feladata az egyes lehetséges építőelem-sorozatok
valószínűségének a megbecslése. Ha eltekintünk az ejtésvariációktól, akkor
ezek az építőelem-sorozatok egy az egyben megfeleltethetők egy-egy
betűsorozatnak, azaz a beszéd szokásos írott alakjának. Így jutunk el a
nyelvi modell segítségével végre a beszédfelismerés végcéljához, a beszéd írott
alakra való leképezéséhez.
A nyelvi modell
feladata tehát az egyes lehetséges betűsorozatok valószínűségének
megadása. Az angol nyelv esetében ehhez egyszerűen a szavak
valószínűségét szokták közelíteni, az 1. fejezetben leírt
gyakoriság-számlálásos technikával (illetve annak finomabb változataival).
Olyan nyelvek esetén, mint a magyar, ez nem célravezető a ragozás miatt;
használható statisztikai nyelvi modell valószínűleg csak a morfológia
figyelembevételével készülhet. Továbbmenve, a nyelvi modell nyilván tovább
javítható, ha olyan magasabb szintű információkat is figyelembe vesz, mint
a szintaxis, szemantika és pragmatika. A beszédfelismerő mindenesetre csak
egy valószínűség-értéket vár a nyelvi modelltől; hogy az hogyan állt
elő, az már a nyelvi modell saját belügye.
d, A dekóder. Egy beszédjel teljes felismeréséhez háromféle információt kell
összegyúrni: a beszédjelből kinyert akusztikus információt, az
akusztikai-fonetikai modell és a nyelvi modell „véleményét”. Ezt a kombinálási
lépést a szakirodalom „dekódolásnak” nevezi, és valójában nem egyébből
áll, mint óriási mennyiségű hipotézis vizsgálatából, és a hipotézisek
közül a legvalószínűbb kiválasztásából (a Bayes-elvnek megfelelően).
A nagyszámú hipotézis átvizsgálására azért van szükség, mert nem tudjuk, hogy
az adott beszédjel milyen fonémákból áll, és azok pontosan hol helyezkednek el
a jelben. Ezért egyszerűen megvizsgálunk minden lehetőséget. Ez az
alábbiak szerint zajlik:
Egy hipotézis kétfajta
feltételezést tartalmaz: egyrészt feltételezi, hogy a jel egy adott fonetikai
sorozatnak felel meg; másrészt feltételez egy adott szegmentálást is, tehát
feltételezi a fonémák pontos helyét is. A hipotézis jóságának
valószínűsége három dologból tevődik tehát össze: egyrészt annak a
valószínűségéből, hogy ez a fonéma-sorozat egyáltalán előáll; a
másik tényező, hogy a fonémák pont ott helyezkednek el, ahol; végezetül,
hogy a fonémák úgy néznek ki, ahogy jelen esetben a hozzájuk rendelt jelrészlet
kinéz. Az első tényező valószínűségét a nyelvi modell adja meg;
a másodikét a fonémák hossz-valószínűségeiből kapjuk; a harmadikat
pedig az akusztikai-fonetikai modell adja meg, minden egyes jelrészlet-fonéma
párra. A valószínűségeket a szorzat-szabály segítségével gyúrjuk össze
egyetlen, az adott hipotézishez rendelt értékké.
A fenti számítást elvégezzük az összes lehetséges
hipotézisre, és a legjobbat tartjuk meg eredményként. Az összes hipotézis
végigvizsgálása természetesen rendkívül műveletigényes, és rengeteg
trükköt használnak a keresés meggyorsítására; a felismerés alapelve azonban
megegyezik a leírtakkal.
4.
Előnyök és hátrányok
A statisztikai
megközelítés előnyei:
A statisztikai
megközelítés legnagyobb előnye, hogy egy jól definiált matematikai eszközt
ad kezünkbe a probléma megoldására. Különösen vonzóvá pedig az a bizonyítás
teszi, miszerint a módszer optimális eredményt garantál – feltéve, hogy mindent
jól csinálunk.
A statisztikai
megközelítés hátrányai:
A statisztikai
megközelítés arra az alapfeltevésre épül, hogy a felhasználás során pontosan
úgy viselkednek a dolgok, ahogy a tanítás során. A statisztikai módszer
kudarcot vall, ha a tanítás és a felhasználás körülményei eltérőek, vagy
bármi más okból olyan szituációban kellene a rendszernek döntést hoznia,
amilyet a tanítás során nem látott. A beszédjelek pedig annyira változatosak
képesek lenni a beszélőtől, zajtól, mondanivalótól stb. függően,
hogy a felismerőket lehetetlen minden eshetőségre felkészíteni,
akármennyi tanító adatot gyűjtünk is.
Habár a statisztikai megközelítés mögött
precíz matematikai levezetések húzódnak meg, a beszédfelismerésben való
alkalmazás során egy csomó irreális feltevéssel éltünk. Mivel lehetetlen minden
lehetséges mondat minden lehetséges kiejtéséről statisztikát készíteni,
ezért a mondatokat felbontottuk fonémákra, a jelet pedig keretekre. Az ezekhez
rendelt valószínűségeket pedig a
szorzás-szabállyal kombináltuk össze. Ez lehetővé teszi a
matematikai modell leegyszerűsítését és gyors számítását, viszont a
mögötte meghúzódó függetlenségi feltevés nyilvánvalóan irreális. Nem
veszítjük-e el a modell matematikai optimalitásából származó előnyöket, ha
a modell nem felel meg a valóságnak, amit le kellene írnia? Másszóval, van-e
értelme milliméterben mérni, ha láncfűrésszel fogunk vágni?? Azt azonban hangsúlyozni kell, hogy ezek a
kételyek nem a statisztikai modell gyengeségeiből fakadnak, hanem a
konkrét felbontásból, amit alkalmaztunk.
Néhány
javasolt javítási lehetőség:
A jelfeldolgozási
lépésen mindig lehet javítani. A hallás működésére vonatkozó ismeretek, ha
némi késéssel is, de apránként bekerülnek a beszédfelismerők feldolgozási
algoritmusaiba. Jó lenne, ha a fonetika is utat találna a felismerőkbe.
Ez hangsúlyozottan igaz
az akusztikai-fonetikai modellre. Hogy a HMM az egyes beszédkeretekhez rendelt
valószínűségekkel dolgozik, annak pusztán két oka van: a kényelmes és
egyszerű kezelhetőség (mind matematikai, mind számítástechnikai
értelemben), és a – hagyomány. Az ugyanis teljesen egyértelmű, hogy az
emberi hallás nem 30 ezredmásodperces darabkákban dolgozza fel a beszédet.
Ehelyett inkább egyfajta „akusztikai eseményekre” figyel, és ezek segítségével
azonosítja a fonetikai megkülönböztető jegyeket. Továbbmenve, a
szorzás-alapú kombinációra is a matematikai modell egyszerűsítése miatt
van szükség. A valóságban az információ redundánsan van kódolva a beszédben,
azaz általában az akusztikai események egy részének érzékelése is elégséges a
beszédértéshez. A szorzás-szabály viszont az események függetlenségét
feltételezi. Úgy véljük, hogy szükséges lenne az alternatív
információ-kombinálási stratégiák kutatása.