Megerősítéses tanulás
A kurzuson eddig felügyelt gépi tanulással foglalkztunk. Ebben a leckében a gépi tanulás egy másik részterületével, a megerősítéses tanulással ismerkedünk meg. A felügyelt tanulással ellentétben megerősítéses tanuláskor nem előre összegyűjtött példákból, hanem a környezettel való interakcióból tanulunk. Leginkább a robotikai felhasználása és az autók önvezető funkcióiból miatt ismert, de gyárak optimalizálására vagy személyreszabott ajánlórendszerekre is alkalmazzák. Segítségével az embernél jobb eredményt sikerült elérni olyan játékokban, mint a go, a sakk, vagy éppen a StarCraft.

A megerősítéses tanulás lényege, hogy egy ágens, interakció lép a környezettel és a környezetből érkező visszajelzések alapján tanul. A tanulás folyamatát az alábbi ábra szemlélteti:
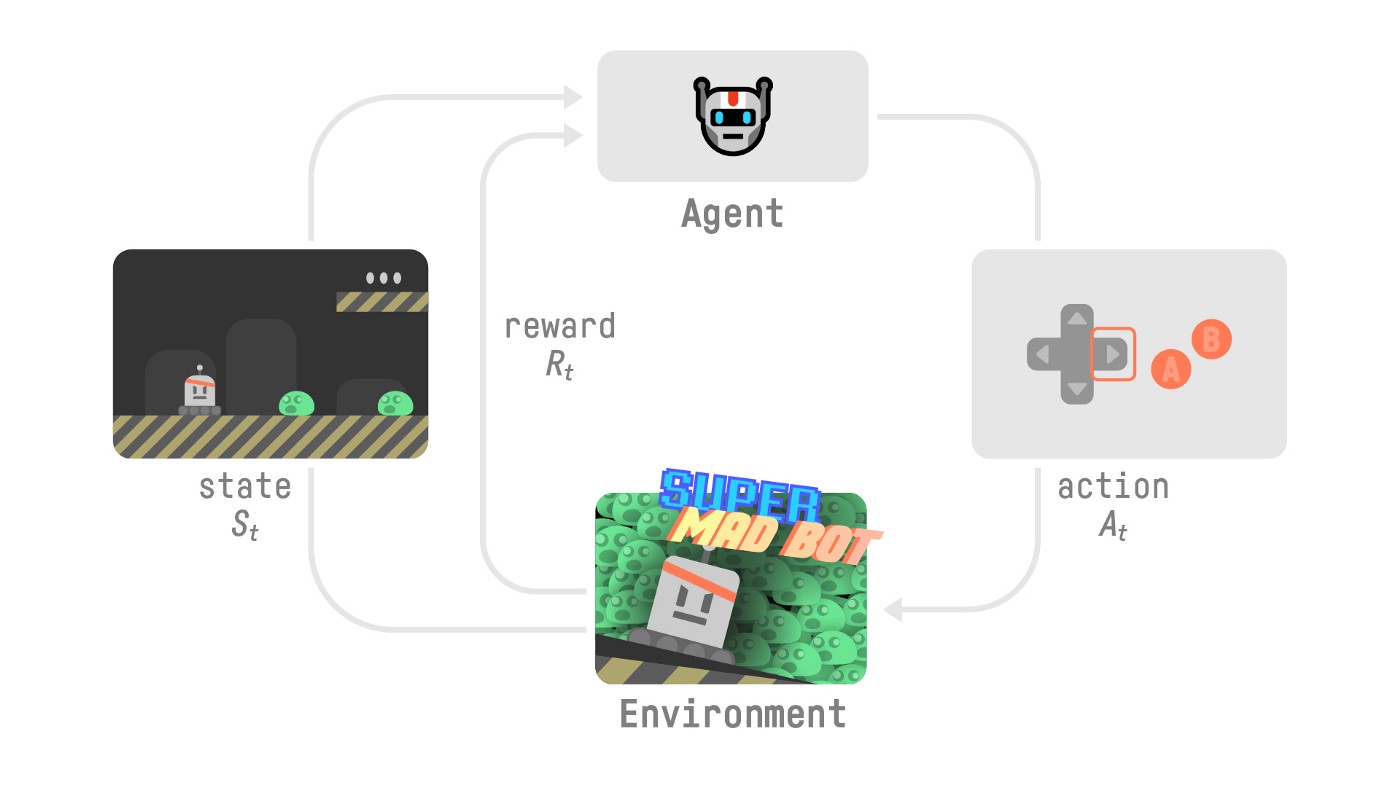
Tegyük fel, hogy az ágensünkkel az a cél, hogy minél tovább tudjunk eljutni egy videójátékban. Az ágens megkapja a környezettől a jelenlegi St állapotot. Az állapot ismeretében kiválasztja az általa legjobbnak ítélt akciót (pl: jobbra megy), aminek a hatására a környezet állapota megváltozik, új St+1 állapotba kerül. Annak függvényében, hogy mi történt az akció következtében, a környezet meghatározza a Rt+1 jutalmat, ami lehet pozitív (például: sikeresen túljutottunk egy akadályon) vagy negatív (büntetés) (például: leesett egy szakadékba). A környezet az új St+1 állapotot és egy Rt+1 jutalmat átadja az ágensnek. Az ágens a döntéseire kapott jutalmakból tud tanulni.
Megerősítéses tanulás során a cél a lehető legtöbb jutalom összegyűjtése, azaz nem a következő lépésben összeszedhető jutalomra, hanem jövőben összeszedhető összes jutalomra optimalizálunk.
Exploration / exploitation trade-off
A megerősítéses tanulás során az egyik legnagyobb dilemma, hogy a lehető legtöbb jutalom elérésének az érdekében mikor kell az ágensnek új még ismeretlen utakat felfedeznie (exploration) és mikor kell a már ismert lehetőségek közül a legjobbat választania (exploitation).
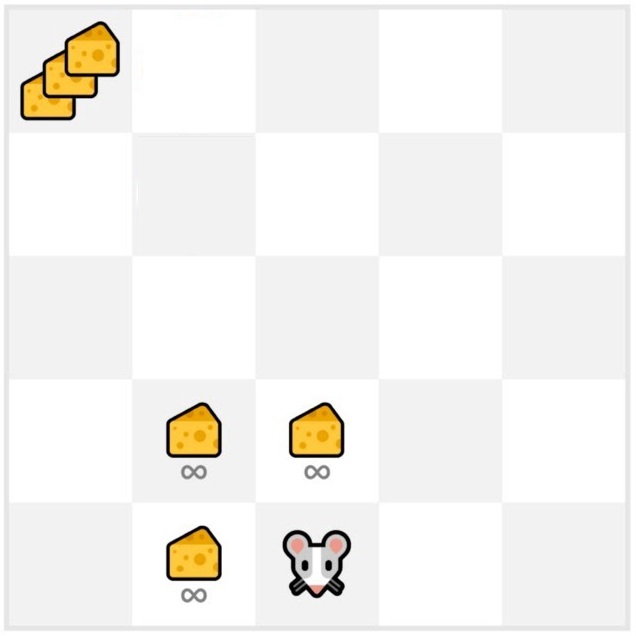
Vegyük a fenti képen látható példát. Tegyük fel, hogy az egér csak azoknak a mezőknek a tartalmát ismeri, ahol járt már és a melette lévő sajtokért +1 jutalom jár, a bal-felső sarokban lévő extra sajtért pedig +1000. Itt az egér nagyon könnyen megtalálhatja a szomszédjában lévő sajtokat, és a végtelenségig fogyaszthat belőlük. Ha nem próbál meg új utakat akkor sosem érheti el az extra sajtot, viszont, ha nem lenne extra sajt, akkor a keressel fölösleges időt veszítene, amíg ehetné a szomszédjában lévő sajtokat.
A problémára rengeteg megoldás létezik, ezek közül az egyik legegyszerűbb az úgynevezett Epsilon-mohó (ε-greedy) algoritmus, aminek a lényege, hogy egy előre megadott ε valószínűséggel felfedezünk, azaz egy véletlen döntést hozunk, és 1-ε valószínűséggel pedig az ismereteink szerinti legjobb döntést hozzuk.
Ez a probléma emberként is ismerős lehet, tegyük fel, hogy nyílt egy új étterem a városban és a kérdés, hogy kipróbáljuk-e azt, vagy inkább egy megbízható helyre megyünk, ahol már sokszor voltunk.
Megerősítéses tanulási algoritmusok
A megerősítéses tanulási algoritmusokat általában az alapján szoktuk csoportosítani, hogy érték-alapú (value-based) vagy stratégia-alapú (policy-based) módszerekről van-e szó.
Az érték-alapú módszerek egy adott állapotból kiinduló összes akcióhoz egy értéket tanulnak, ami azt próbálja megbecsülni, hogy az adott állapotból az adott akció hatására mennyi jutalmat lehet összeszedni a jövőben. Az egyes akciók közül azt választják, amelyikhez a legnagyobb érték tartozik, azaz amelyik a legtöbb jutalmat ígéri. Ebbe a kategóriába tartozik például a Q-tanulás.

Ezzel szemben a stratégia-alapú módszerek közvetlenül az egyes döntések valószínűségét próbálják megbecsülni a jövőben összeszedhető jutalom ismerete nélkül. Az érték-alapú módszerekkel szemben előnyük, hogy könnyen alkalmazhatók folytonos akcióterekben (például: hány fokkal forgassuk el a kormányt? Végtelen akciónk van, így nem lehet minden akcióhoz értéket rendelni, viszont például normál eloszlás alapján becsülhetünk egy valószínűségi eloszlást stratégia-alapú módszerrel). Hátrányuk viszont, hogy kevésbé stabilak, és általában több környezettel való interakció szükséges egy ugyanolyan teljesítményű modell megtanulásához.
Manapság nagyon elterjedtek az úgynevezett Actor - Critic módszerek, mint a PPO amik kombinálják a két irány előnyeit.