Egyszerű döntési szabályok
A gépi tanulás során a tapasztalat halmaz, amiből a gép javítja teljesítményét, adatrekordok formájában áll rendelkezésre. Ahhoz, hogy a mérnök igazán jó gépi tanuló rendszert tudjon építeni, szükségünk van ezen adathalmazok megértésére, főbb statisztikai tulajdonságainak ismeretére. A gépi tanulási fejlesztési ciklusban az alábbi helyeken van erre szükség:
- Megérteni a problémát, és ez alapján az adatforrásokat, jellemzőket, kiértékelő függvényt definiálni.
- Az adathalmazok statisztikáiből létrehozhatunk egyszerű döntési szabályokat, amik általában jó - igaz első, de működő - verziók.
- Az aktuális modell kiértékelése után az adatelemzés segít a mérnöknek megérteni a rendszer gyenge pontjait, ahol javítani kell azon.
Leíró statisztikák
Nézzünk egy újabb gyakorlati feladatot! A student performance adatbázisban diákok adatai találhatóak meg. Azt akarjuk
megjósolni, hogy melyik diák fogja sikeresen elvégezni a kurzust ( azaz \(G_3 \ge 10\) ).
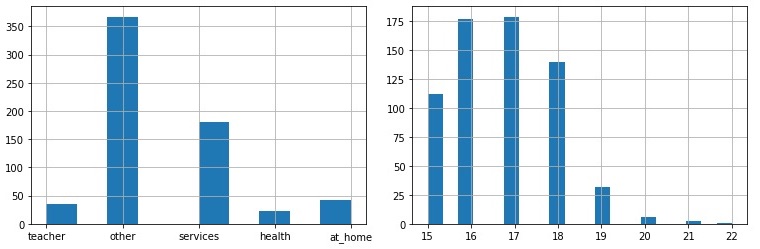
Vizsgáljuk meg mondjuk az életkor (age) és az apa foglalkozása (Fjob) változókat! Az age folytonos, míg az Fjob diszkrét jellemző.
Egy kép többet mond ezer szónál! A hisztogram x tengelyén a vizsgált
változó értékei találhatóak, az y tengelyen pedig az értékek adatbázisbeli gyakoriságait látjuk. Numerikus változók esetén kisebb, egyenlő
méretű intervallumokra (bin) bontjuk az értékkészletet, az intervallumba eső adatok gyakorisága olvasható le az y tengelyről.
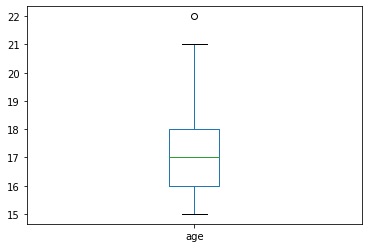
- Legkisebb (min) és legnagyobb értékek (max).
- Átlag: a megfigyelt értékeket összeadjuk, majd osztjuk az elemszámmal.
- Medián: a megfigyelt adatokat nagyság szerint rendezzük, és kiválasztjuk a középső elemet.
- Kvartilisek: hasonlóan a mediánhoz, a megfigyelt adatok nagyság szerint rendezzük. A sorozat 1/4-édénél lévő értéket alsó-, míg 3/4-édénél lévő értéket felső kvartilisnek nevezzük.
- Szórás: a megfigyelt értékek átlagosan mennyivel térnek el az átlaguktól.
Egyszerű statisztikai döntési szabályok
Ahogyan az a gépi tanulási ciklusnál tárgyaltuk, érdemes először egy egyszerű döntési rendszert építeni, megérteni annak hibáit, mert ez fog segíteni a komolyabb rendszer fejlesztésében. Ezek az alap (baseline) megoldások abban is támpontot nyújtanak, hogy tanult-e valami hasznosat a rendszerünk. Ha ugyanis nem sikerül jobb - vagy csak kicsivel jobb - eredményeket elérnünk egy bonyolult, erőforrásigényes gépi tanuló rendszerrel, mint az egyszerű alap döntési szabály, akkor nem tudott tanulni a rendszer. Ennek számos oka lehet, a tanító adatbázisunk nem elég nagy vagy a jellemzőkészletünk nem informatív vagy rossz modellt választottunk. Mindenesetre a baseline megoldáshoz érdemes hasonlítani a szofisztikáltabb gépi tanuló rendszerek teljesítményét.
Konstans döntések
A legegyszerűbb döntési szabály (baseline) úgy számolható a tanító adatbázisból ha az egyedek jellemzőit nem is vesszük figyelembe, csak
a célváltozót figyeljük meg, és minden predikciónál konstans értéket jóslunk. Ha a célváltozónk diszkrét érték (osztályozási feladat), akkor
mindig jósolhatjuk a tanító adatbázis leggyakoribb osztályát (most frequent class baseline). Ha a célváltozónk folytonos érték (regressziós feladat), akkor
jósolhatjuk mindig a tanító adatbázisból leszámolt átlagot vagy mediánt.
Jelen példánál, ha a kurzus teljesítésének sikerét (osztályozási feladat {megfelelt, nem felelt meg} két osztállyal) akarjuk megjósolni, akkor
ez a baseline mindig megfeleltet fog dönteni:
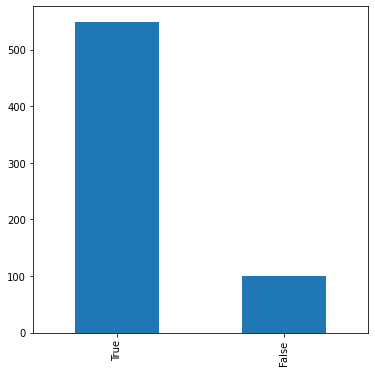
Döntés egyetlen jellemző alapján
Valamivel szofisztikáltabb - de még mindig nagyon egyszerű - döntési szabályokat írhatunk ha az egyedeket leíró jellemzőket külön-külön megvizsgáljuk olyan szempontból, hogy az adott jellemzőre épített döntési szabály mennyire jól teljesít. Egy diszkrét jellemzőre épített döntési szabály lehet HA Fjob=teacher AKKOR predikálj 14.5-öt. Egy folytonos jellemzőre épített szabály lehet például HA age>17 AKKOR predikálj megfeleltet. Ezekhez a döntési szabályokhoz a kérdéses jellemző és a célváltozó kapcsolatát kell megértenünk.
Ha osztályozási feladatunk van és diszkrét jellemzőt vizsgálunk (két diszkrét jellemző összehasonlítása) akkor a színezett eloszlás segíthet:
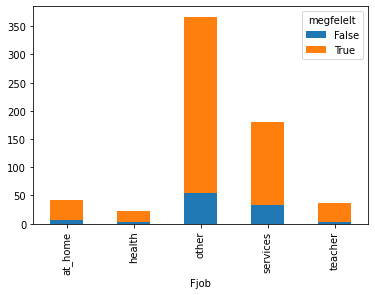
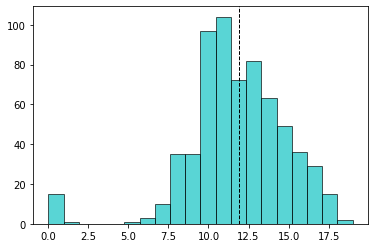
Ha osztályozási feladatunk van és folytonos jellemzőt vizsgálunk, akkor a különböző osztályokba eső elemek hisztogramjainak összehasonlítása segíthet:
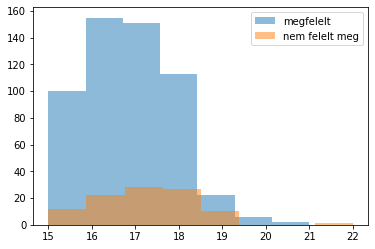
Ha regressziós feladatunk van (a célváltozó folytonos), akkor az előző módszer használható diszkrét jellemzők hatásának vizsgálatára. Két folytonos változó
összehasonlítására (például egy jellemző és a célváltozó) a scatter plot a legalkalmasabb:
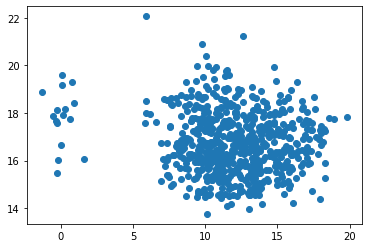
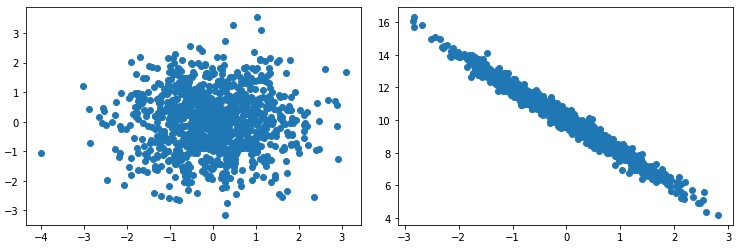
Ebben a leckében, a tanító adatbázis statisztikái alapján, kézzel fogalmaztunk meg döntési szabályokat. Természetesen lehetne bonyolultabb döntési szabályokat is megfogalmazni, ami több jellemző értékét is felhasználják. A következő leckétől kezdve "igazi" gépi tanulási algoritmusokkal fogunk megismerkedni, amelyek a tanító adatbázis alapján maguk építik fel a modellt/döntési szabályokat, a gépi tanulási mérnöknek "csak" a tanulási környezetet kell felépítenie, kiértékelni, megérteni és finomhangolni...