Mély gépi tanulás (deep learning)
A mély gépi tanulás (Deep Learning) a gépi tanulási technikák egy alcsoportja, amiben mesterséges neurális hálózatokat (Neural Networks) használunk. Tehát minden gépi tanulási feladat ami mély gépi tanulással megoldható, megoldható "klasszikus" gépi tanulási módszerekkel is. A fordított irányra ez már nem igaz, ugyan a legtöbb gépi tanulási problémára adható mély tanulási megoldás, de nem mindegyikre. A deep learning a 2010-es években nagyon elterjedt, divatossá vált, de nem minden gépi tanulási feladatra alkalmazható csodafegyver. Mindig a problémához/feladathoz válasszuk meg a legmegfelelőbb eszközt és ne erőszakoljunk rá egy megszokott módszert minden feladatra!
Neurális hálózatok
A mesterséges neurális hálózatok a biológiai idegrendszer (pl. az emberi agy) információfeldolgozásának működését próbálják utánozni. Nagyszámú, erősen összefüggő, együttműködő processzáló elemek, a neuronok végzik a számítások alapegységeit. Egy neuron az \(x\) bemeneti értékek \(w\)-vel súlyozott lináris kombinációját számolja ki, majd egy nem-lineáris \(f\) aktivációs függvényt alkalmaznak. Azaz egy neuron \(y\) kimeneti értéke: \[y = f( \sum\limits_{i = 0}^d {w_i a_i} ) \]
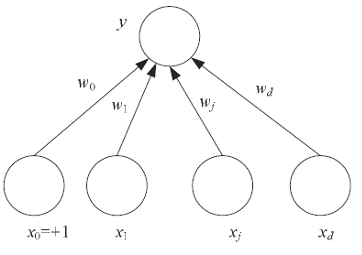
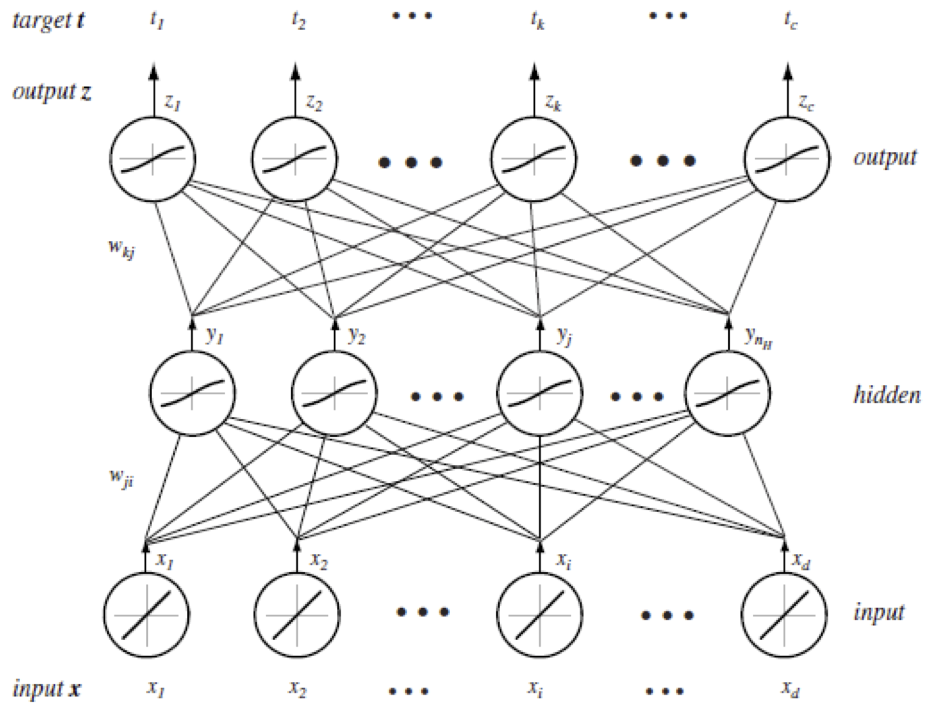
A neurális hálózatok a neuronok ún. rétegeiből (layer) épülnek fel. Az információ csak rétegről rétegre, egy irányba, előre (forward), a bemeneti rétegtől (input layer) a kimeneti réteg (output layer) felé, vagy hátrafelé (backward), a kimeneti rétegtől a bemeneti felé terjedhet. Csak az egymást követő rétegek közt vezetnek élek, egy rétegen belül, réteget "átugorva" nem vezetnek élek.
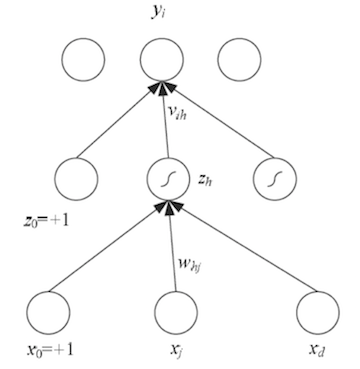
Neurális hálózat tanítása
A neurális háló tanításánál a cél a \(w\) élsúlyok beállítása, úgy hogy a legutolsó, kimeneti rétegen a neuronok értéke a lehető legközelebb kerüljön az elvárt értékekhez, azaz minimalizáljuk a hibát.
Ha regressziós feladatunk van, egyetlen kimeneti neuron van és használhatjuk az MSE-t a hiba mérésére. Ha osztályozási feladatunk van, akkor ahány osztálycímke van, annyi kimeneti neuronunk van és predikciós időben, amelyiknek a legnagyobb a kimeneti értéke, az az osztálycímke lesz a predikció. Többcímkés osztályozási feladatoknál a kereszt entrópiát (cross entropy) használjuk hibafüggvényként. Itt a tényleges \(t\) (target) értéket 1-re állítjuk a megfelelő osztálynál és mindenhol máshol 0-ra. A hibafüggvény a \(t\) tényleges értékek és a predikált \(z\) kimeneti értékek közti hasonlóság (a két valószínűségi vektor kereszt entrópiája).
A neurális hálók tanítása ún. online gépi tanulási módon történik, ami azt jelenti, hogy egyetlen tanítópéldával tudjuk frissíteni a w súlyokat. Ehhez az aktuális súlyokkal (=modellel) predikálunk, kiszámoljuk a hibát majd a kimenetről visszafelé terjesztjük/elosztjuk a hibát a megelöző réteg neuronjai közt (backpropagation). Mivel a tanító példák sorrendje nem számít, ezért általában összekeverjük azokat és egyessével adjuk be a tanuláshoz. Ahhoz, hogy a (nagyon) sok súlyt be tudjuk kalibrálni, általában többször végigmegyünk a tanító adatbázisunk példáin. Epochnak hívjuk azt amikor a tanító adatbázisunk összes példáját egyszer odaadtuk a tanításhoz.
Túltanulás elkerülése
A neurális hálóknak a túltanulás elkerülésére minden tanulási iteráció (epoch) után, a validációs halmazon kiértékeljük a modellt. Ha elkezdenek az eredmények romlani akkor leállítjuk a tanulást, ugyanis akkor valószínűleg túltanultunk, azaz "bemagoltuk" a tanító adatbázist és az azon kívüli példákon már nem teljesít jól. Azaz a túltanulás-általánosítási meta-paraméter a neurális hálóknál az epochszám.
Mély gépi tanulás
A mély gépi tanulás (deep learning) olyan neurális hálózatokat jelent, amelyekben több rejtett réteg található, azaz "mély".
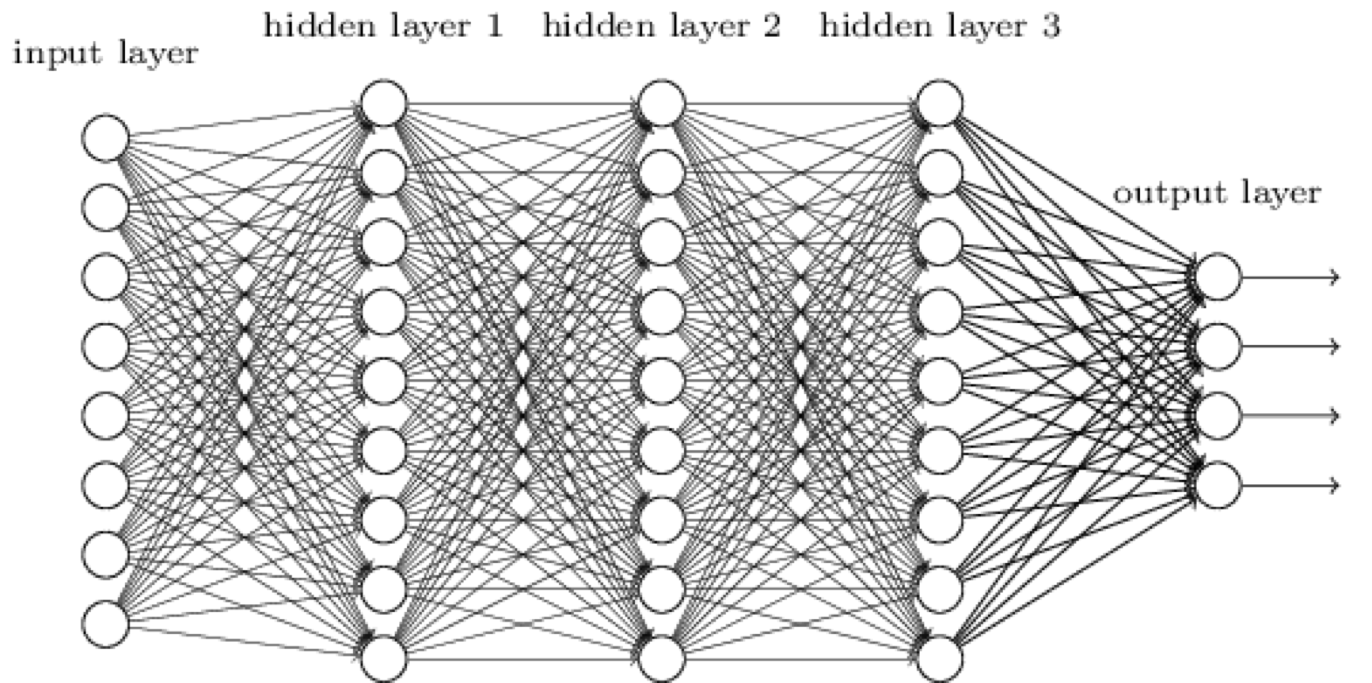
Az intuíció a több rejtett réteg mögött az, hogy minden réteg egy másfajta, egyre absztraktabb reprezentációját képes adni a bemeneti adatnak. Mivel az egyes rétegek különböző reprezentációt adnak, ezért kiindulhatunk nyers adatokból is, nincs szükség jellemzőkinyerésre, hiszen az alsóbb rétegek felfoghatóak úgy, mint nyersadatból jellemzőkinyerés és - a klasszikus gépi tanulási módszerekkel szemben - itt nem kell kézzel jellemzőket definiálnunk, a háló megtanulja azokat.
Mivel így már sok százmillió súlyt kellene tanulnunk, ezért különböző trükkökre van szükségünk, hogy a mély hálók a gyakorlatban is működjenek.
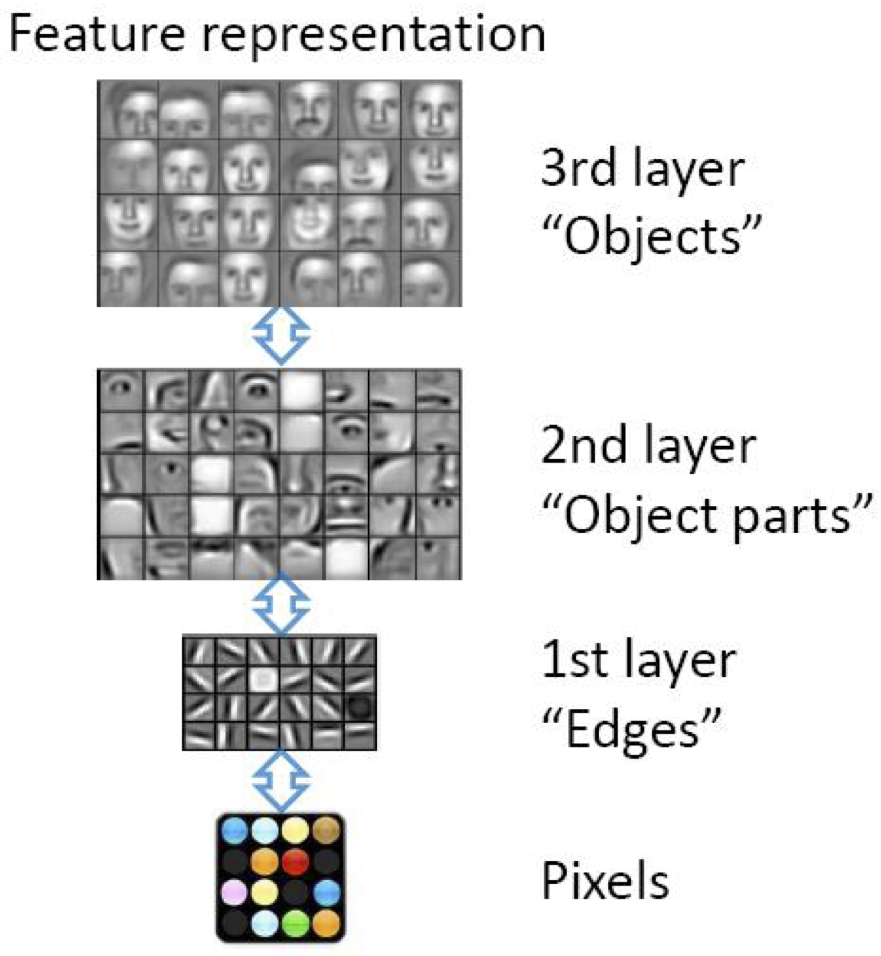
Konvolúciós hálózatok
Egy tömörítési trükk a konvolúciók használata. A Konvulúciós Neurális Hálózatok (Convolutional Neural Networks, CNN) egy olyan speciális hálózat, amiben mozgó ablakokkal/szűrőkkel tömörítjük a bemeneti információt. Az ablakok megosztják a \(w\) súlyaikat, azaz ugyanazokat a súlyokat tanuljuk a következő rejtett réteg minden egyes neuronjához, ezzel drasztikusan csökkentve a tanulandó súlyok számát.
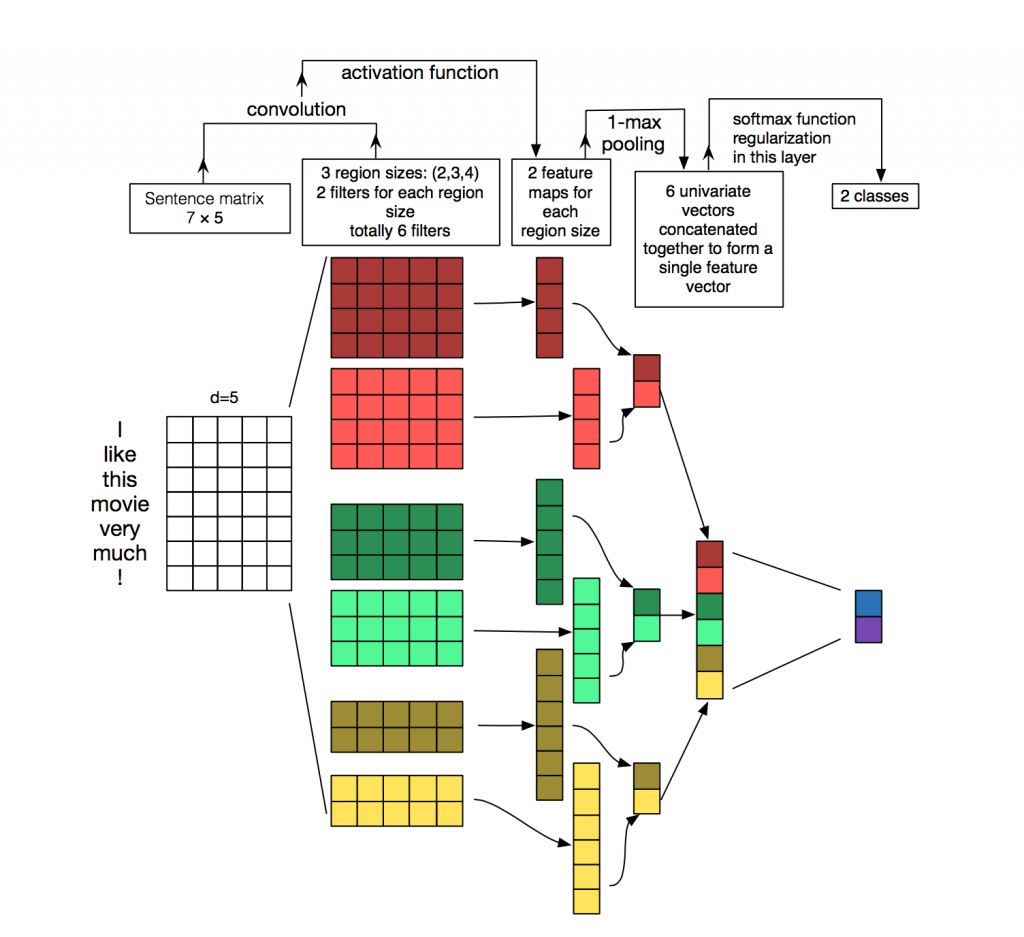
Például egy szövegosztályozási feladatnál ha van egy 20 szavas szövegünk és minden szót egy 100 dimenziós szóbeágyazás ír le akkor egy teljesen összekötött (dense) neurális hálóban ha 200 rejtett neuronunk van akkor 20*100*200=400K súlyt kell kalibrálnunk. Ha ehelyett 5 hosszú konvolúciós ablakot használunk, azaz a megelöző és rákövetkező két szó esik bele minden egyes szövegszóhoz, akkor csak az 5*100 súlyt kell megtanulni, hiszen ugyanazokat használjuk minden szövegpozícióban, majd alkalmazunk egy maximum műveletet a 200 rejtett dimenzióra csökkentésre (max pooling).
Mély gépi tanulás vs "klasszikus" gépi tanulási technikák
Előnyei a másfajta ("klasszikus") gépi tanulási technikákkal szemben:
- Képesek viszonylag nyers adatokból kiindulni, jóval kevesebb a jellemzőtér kialakításának a szerepe.
- Bizonyos alkalmazási területeken (pl. beszéd- és képfeldolgozás) sokkal jobb eredményeket érnek el, mint a korábbi gépi tanulási megoldások.
- A neurális hálózat egy általános modell reprezentáció, különböző feladatokra is ugyanazon reprezentáció használható.
Hátrányai:
- Csak akkor tud viszonylag nyers adatból tanulni, ha nagyon sok adatból áll rendelkezésre a tanuláshoz (és az előfeldolgozás azért itt is nagyon fontos).
- Számításigénye sokszorosa a klasszikus gépi tanulási módszerekének.
- Black-box: a gépi tanult modell (=összefüggések, szabályszerűségek) nem értelmezhetőek ember számára, nem úgy mint a klasszikus gépi tanulási módszereknél.