Generatív mesterséges intelligencia
A 2022-es évben robbant be a mesterséges intelligencia igazán a köztudatba. Az év eljén jelent meg a DALL-E, ami néhány kulcsszó alapján legenerál egy olyan képet, ami még korábban nem létezett. Az év végén pedig kijött a ChatGPT, ami szöveges utasításokra szöveget generál. Mindeközben a szoftverkódot generáló megoldások is (pl Github Copilot) is felhívták magukra a figyelmet.
Ezeknek a szöveget, képet vagy szoftverkódot genereló megoldásoknak a felépítése teljesen azonos gépi tanulási szemszögből. Mindegyik lelke egy óriási jelöletlen adaton előtanított beágyzás. A beágyazást kódoló neurális hálókat pedig finomhangolták generálási feladatokra (azaz felügyelt gépi tanulást használtak). Például a szöveggenerálás visszavezethető arra az osztályozási feladatra, hogy adott egy szöveg és a gépnek meg kell jósolnia, hogy a 100 ezer leggyakoribb angol szó közül melyikkel folytatódik a szöveg. Vagy ha egy képrészlet legenerálása visszavezethető egy regressziós feladatra, hogy az első generálnadó pixelnek mennyi legyen az RGB értéke a szomszédos, ismert pixelek, mint jellemzők alapján. Az olvasólecke hátralévő részében három generatív alkalmazással megismerkedünk egy kicsit részletesebben.
Szöveggenerálás
A ChatGPT alapja a GPT-3.x nagy nyelvi modell család. A GPT típusú beágyazásokat az interneten elérhető (de gondosan szűrt) szövegeken előatanították arra a feladatra, hogy adott egy bizonyos hosszúságú szósorozat, akkor lehetséges angol szavak szótárából meg tudja jósolni, hogy melyik szó követi a szósorozatot. Ehhez az internetről gyűjtött jelöletlen szövegekből önfelügyelt módon fogalmazták meg azt az osztályozási feladatot. Az osztályozót utána lehet arra használni, hogy tetszőleges szósorozat után legenerálja a legvalószínűbb következő szót.
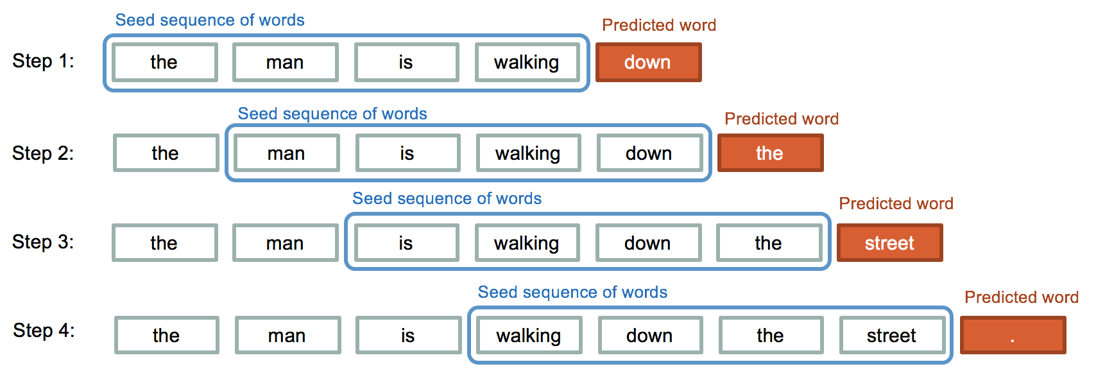
A ChatGPT a GPT finomhangolt verziója, ami egy olyan tanító adatbázist használ a finomhangolásra, ahol emberi instrukcióra emberek válaszoltak (a generatív LLMek instrukció-megoldás párokkal történő finomhangolását instruct-tuningnak is szokták hívni). Így a szöveggenerálás nyelvtanilag és tartalmilag helyes szövegeket generál szavanként a GPT nyelvi modellnek köszönhetően, miközben az instrukciókra adott emberi válaszok alapján finomhangoljuk a válaszok stílusára, a különböző típusú instrukciókra adott válasz formátumára és az etikai problémákba ütköző kérdések kikerülésére.
Képrészlet generálása
Hogyan működnek a képekről objektumot eltávolító megoldások? Egy felismert vagy kijelölt objektumot el akarunk távolítani egy képről, akkor le kell generálnunk az objektum által kitakart képrészletet. Ez a kép megmaradó részei alapján történik:

Ennek alapja is egy képeket hatékonyan kódoló beágyazás, amit finomhangolhatunk egy generálási feladatra. Finomhangolási tanító adatbázist könnyedén elő tudunk állítani, hiszen ha igazi képekből letakarunk egy részletet, akkor a predikció célja, hogy a letakart képrészletet (vagy ahhoz minél hasonlóbbat) generálja le. Az egyszerűség kedvéért elképzelhetjük a generálási folyamatot úgy, hogy pixeleket egyessével generálva töltjük fel a kitakart képrészletet (a gyakorlatban ez szofisztikáltabban működik).
Képgenerálás szöveges promptból
Ha egy szöveges utasításra szeretnénk teljesen új képet generáltatni (pl. DALL-E) akkor ott a szövegbeágyazásoknak (LLMek) és a képbeágyazásoknak együtt kell tudni működnie. Ezt egy speciális önfelügyelt tanítási módszerrel (contrastive learning) érhetjük el, ahol az internetről letöltött óriási mennyiségű kép-képaláírás párt használhatunk arra, hogy egy előtanított LLM és egy előtanított képbeágyazás közti átjárást megteremtsük.
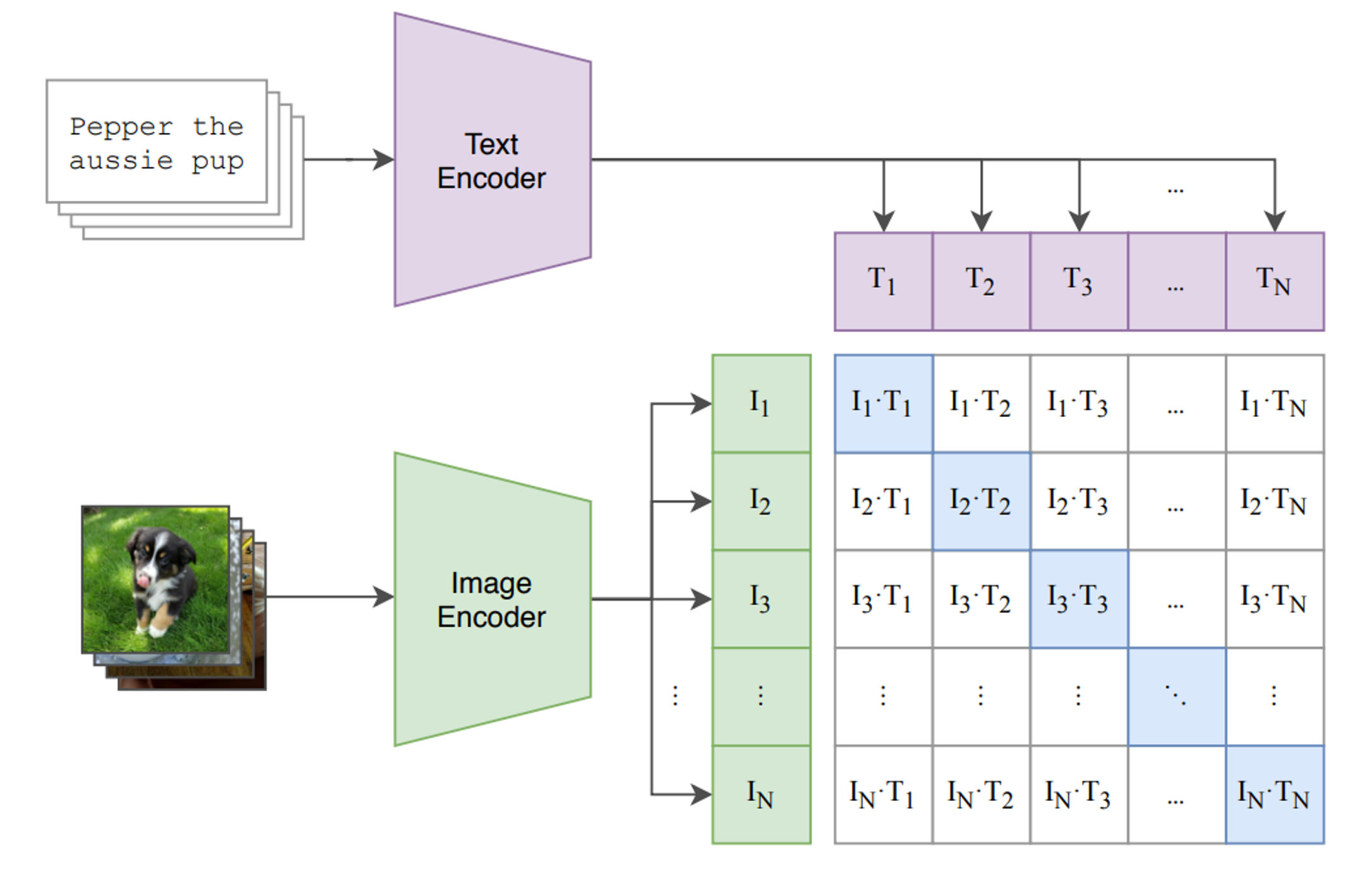
Maga a szövegből kép generálás ezen összehangolt beágyazások felett működik. A diffúziós modellek a képgenerálást visszavezetik képzajmentesítési feladatra. Az alapgondolat az, hogy van egy zajos képünk, de tudjuk annak tartalmát (szövegesen megadva), akkor a szöveges leírás alapján még a nagyon zajos képekből is helyre tudunk állítani egy képet, ami megfelel a leírásnak. Ha ez működik, akkor véletlenszerűen generált képzajból kiindulva is tudunk a tartalmi leírás alapján "zajt csökkenteni", azaz egy teljesen véletlen zajképből egy olyan képet generálni, ami megfelel a tartalmi leírásnak.
A zajcsökkentés megint egy önfelügyelt tanítási megoldás. Tanító adatbázist építhetünk úgy, hogy képekhez mesterségesen, több lépésben, zajt adunk, egészen addig amíg már felismerhetetlen lesz az eredeti kép (encoder). A képhez tartozó képaláírás leírja, hogy mi volt a kép vizuális tartalma, azaz ha visszafordítjuk a folyamatot, akkor lesznek felügyelt tanító példáink arra, hogy egy tartalmi leírás és egy zajos képből mi az elvárt zajcsökkentett kép (decoder).
