Research Group on Visual Computation
- Home
- Projects
- TODER Project
- Demo Software
- Open positions
- COSCH Training School 2015
- Publications
- Intranet
Vision Graphs - Collaborative Compositing and View Construction | |
|
|
|
DescriptionWe have many sources for obtaining images of a geographical location, as more and more people share their photos through various online services. We also know of a number of impressive works that tackled the problem of creating panoramic/composite views or 3D reconstructions of locations based on available data. However, most of these methods - probably the most known of which are based on bundle adjustment - require large amounts of computing power, processing photo collections offline. Given a set of well-corresponding image series shot along a continuous path with multiple interest point correspondences enables the production of stitched images and panoramas that can be used for creating location-dependent composite views, even if sensor information (location, orientation, field of view) is limited or unavailable.The main purpose of the proposed method(s) is to be integrated into a collaborative mobile application framework, where users can go to a geographical area, take photos, and then be able to visualize larger composite views of the same area produced by processing the user's photos and the data gathered from other users that are in the same area. To help processing and reduce complexity, we extract and use device sensor data like GPS coordinates, device orientation and field of view (FOV). Such a system would operate without a centralized architecture, devices would connect in a peer-to-peer fashion, and processing would be done locally on the devices. In such scenarios, it is important to provide lightweight methods for image content processing and also for data propagation between the devices. Of course, at some point, photos will need to also be transferred in order to create the composited views, but our intent is to perform as much pre-processing - based on propagated data only - locally as possible, then transfer only those photos which have been deemed relevant for producing the final visualizations. The main points of the introduced work are the following: being lightweight; building and analyzing local vision graphs and applying pre-filtering steps to find corresponding image groups before computing content-based correspondences; filtering matched interest points based on feature-differences and interest point distances and based on extra, local image features (e.g. LBP, texture, edge histogram) to reduce the quantity of interest points and features (retaining only approx. 4-5\% of original interest points); only trying to match images belonging to the same local group/component (as opposed to bundle adjustment processes), which is important when targeting device-only processing; instead of full panoramas, producing a circular distribution view of all obtained images around a location. Main steps:
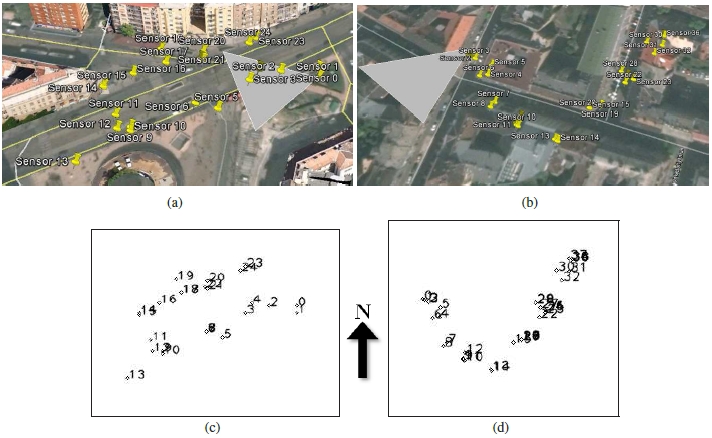 (a),(c): Sensor locations shown in KML on map. (b),(d) Sensor locations visualized for internal processing. 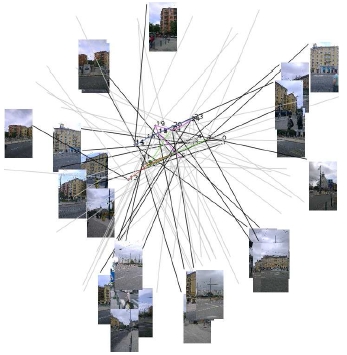 Internal visualization showing all sensors, their orientations, approximate FOVs and the captured images. 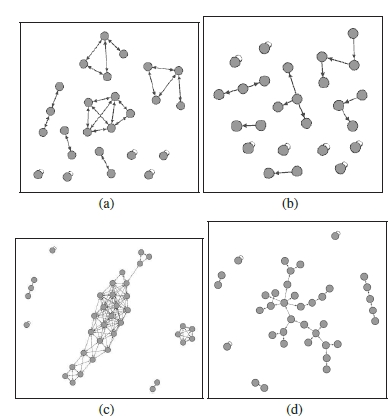 (a),(b): First location: graph node structure before and after content analysis. (c),(d): The same for the second location. 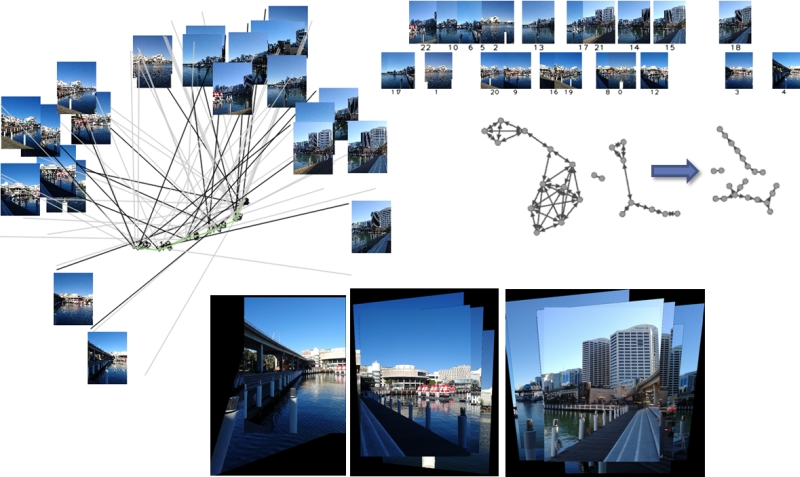 Example view generation. |
- Levente Kovács, Processing Geotagged Image Sets for Collaborative Compositing and View Construction, In Proceedings of ICCV Workshop on Computer Vision for Converging Perspectives, Sydney, Australia, pp. 460-467, 2013. [bibtex]
Hichem Abdellali has been awarded the Doctor of Philosophy (PhD.) degree...
2022-04-30
Hichem Abdellali has been awarded the KÉPAF Kuba Attila prize...
2021-06-24